Exploitations et valorisations des données numériques connexes à l’édition
Les Seint Confessor de Wauchier de Denain
Ariane Pinche
![]()
Ariane Pinche,
« Exploitations et valorisations des données numériques
connexes à l’édition »,
dans
Robert Alessi,
Marcello Vitali-Rosati (dir.),
Les éditions critiques
numériques (édition augmentée), Les Presses de l’Université de
Montréal, Montréal, 2023, ISBN : 978-2-7606-4857-9, https://www.parcoursnumeriques-pum.ca/12-editionscritiques/chapitre7.html.
version 0, 27/03/2023
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA
4.0)
L’édition numérique permet de renseigner un grand nombre d’informations à propos du texte. Si, dans le cadre de l’édition papier, l’éditrice ou l’éditeur est souvent obligé de choisir entre une approche méthodologique et une autre, le texte numérique permet, quant à lui, de multiplier les données et de proposer aussi des lectures et des interprétations parallèles. Cependant il ne faut pas tomber dans le piège d’une sorte d’idéologie d’exhaustivité. Ce chapitre montre le lien entre les modèles épistémologiques et les choix techniques et illustre comment on peut exploiter des informations encodées dans un texte numérique critique. Loin d’être une représentation exhaustive de toutes les sources et de toutes les interprétations possibles, l’édition numérique doit toujours être portée par la volonté de proposer un texte à un lectorat non nécessairement spécialiste ainsi que des données exploitables pour les spécialistes. En s’appuyant sur le cas des Seint Confessor de Wauchier de Denain, il sera ici, encore une fois, question de comprendre comment des approches et des modèles philologiques différents peuvent être implémentés dans des choix techniques particuliers. Il sera montré que chaque choix implique un positionnement théorique qui permet de mettre en avant certains aspects et certaines interprétations du texte en laissant toujours dans l’ombre d’autres possibilités qui serait pertinentes dans d’autres cadres épistémologiques.
Introduction
Toute édition est le fruit d’une époque et d’une école philologique (Trotter 2015, Introduction, 3-6). Les pratiques les plus répandues aujourd’hui dans la philologie médiévale découlent soit de l’école « lachmanienne » qui cherche à rétablir le UrtextTentative de reconstitution de l’archétype, soit un texte idéalement originel (Breuil 2019, 300).↩︎, soit de l’école « bédiériste » qui cherche à établir la transcription du meilleur témoin. La new philogogy depuis les années 1990, influencée par les principes de « mouvance » établis par P. Zumthor (1972) et de « variance » de B. Cerquiglini (1989), invite à non pas établir un texte qui se rapprocherait de celui de l’auteur, notion anachronique pour la période médiévale, mais à s’intéresser à la copie et à ses caractéristiques linguistiques propres. Les différentes approches philologiques ont donné naissance à des pratiques nationales relativement divergentes. Ainsi, la tradition italienne tend vers le néo-lachmanisme et accorde encore beaucoup de place à la reconstruction textuelle, la plupart des éditions françaises suivent la méthode bédiériste, tandis que les Anglo-saxons composent des éditions documentaires ou diplomatiques (Trotter 2015, Introduction, 1-18). Les pratiques peuvent également diverger d’un champ disciplinaire à un autre entre historiens, linguistes, littéraires en proposant des degrés de fidélité à la copie différents« Pour des textes en anglo-normand, par exemple, les éditions des historiens n’ont ni accents, ni apostrophes : on lit ainsi Dangleterre et labbe, au lieu de d’Angleterre et de l’abbé » (Breuil 2019, Introduction, 5).↩︎. Malgré ces divergences méthodologiques« L’absence de méthodologie commune a souvent été reprochée à la philologie, mais cette absence est intrinsèque à la discipline ; la philologie consiste plus en un faisceau de règles méthodologiques qu’en une doctrine homogène » (Carles et Glessgen 2015).↩︎, les éditeurs et éditrices ont un but commun : ils cherchent à réduire l’écart entre le texte et le lectorat moderne pour en faciliter l’accès (Breuil 2019, 675).
L’habitude de travailler avec des éditions imprimées amène souvent de jeunes étudiants et étudiantes de lettres à ne pas réaliser que l’édition d’un texte grec, latin ou en ancien français est extrêmement différente de ce qu’on peut lire directement dans le manuscrit, car l’édition en a lissé les difficultés. Afin de faciliter la lecture, la segmentation des mots a été uniformiséeBien souvent, il n’est pas aisé de voir dans les manuscrits si les mots sont séparés ou pas (planche 7.a), sans même parler des manuscrits écrits en scriptio continua (voir le manuscrit carolingien latin 152 de la BnF).↩︎. Cette étape n’est pas sans impact sur la réception du texte, notamment concernant les élisions et les tmèsesPour désigner une femme enceinte, que retranscrire : en charga, comme sur le manuscrit, ou encharga, comme l’entrée du dictionnaire ?↩︎. Comment transcrire delarbre quand il n’est pas aisé de déterminer où sont les espaces dans le manuscrit médiéval ?
Planche 7.b – Exemple de texte issu de la reproduction Gallica du manuscrit fr. 412 de la Bnf, fol. 106v.

Proposé par auteur le 2023-03-27
Faut-il écrire del arbre avec une enclise de la préposition et de l’article, fréquente en ancien français, ou de l’arbre qui permet une lecture plus aisée ? Ces harmonisations peuvent donner une vision déformée du texte aux novices. Dans les éditions, l’ensemble des abréviations est développé sans nous demander quel est l’impact de ces modifications. Pourtant tout développement est déjà une interprétation. Par exemple, le choix de développer l’abréviation tironienne ⁊ en et ou eForme dialectale de et en anglo-normand.↩︎ dépend de la date et de l’aire géographique de composition de la copie ou du texte. Pour comprendre le processus d’établissement d’un texte, mais aussi l’exploiterÉtudes statistiques d’une scripta, du système abréviatif ou des phénomènes d’agglutination.↩︎, il est important de donner accès aux informations présentes dans les sources avec un minimum d’interprétationLe retour complet à la source ne sera jamais possible sans une consultation de l’objet physique qu’est un manuscrit.↩︎.
L’édition numérique ouvre aujourd’hui la possibilité de conserver plusieurs strates d’établissement du texte en répertoriant les données préliminaires, ce que l’édition imprimée jusque-là ne permettait pas. En effet, l’utilisation de plus en plus répandue dans les communautés scientifiques en sciences humaines et sociales (SHS) du standard xml TEILa Text Encoding Initiative (TEI) est un consortium qui développe et maintient un ensemble de normes pour la représentation des textes sous forme numérique. Les différentes préconisations liées à ce standard sont décrites dans les TEI Guidelines qui spécifient les méthodes d’encodage des textes pour qu’ils soient lisibles par la machine et permettent de traduire les principaux principes d’analyse textuelle dans le domaine des sciences humaines, des sciences sociales et de la linguistique.↩︎ (Burnard 2015) a permis grâce au balisage textuel de consigner des informations de plus en plus nombreuses, mais surtout réexploitables et interrogeables. Concevoir une édition nativement numérique modifie le travail de préparation de l’édition, car contrairement à l’édition traditionnelle où l’imprimé contient l’ensemble des données auxquelles le lectorat aura accès, dans une édition numérique, décrire philologiquement, linguistiquement le texte et en montrer la matérialité ne relève plus d’un même geste. L’objet éditorial peut être démultiplié. Les fichiers xml TEI fonctionnent alors comme une archive de l’ensemble du travail de préparation de l’éditeur qui pourra être ajouté au paratexte de l’édition numérique.
Le travail préliminaire à l’établissement du texte est sauvegardé et les données pérennisées, permettant le contrôle de la qualité du travail scientifique. Afin que les données puissent être comprises correctement et être exploitées en dehors du projet, il est également important de documenter la manière dont le corpus a été encodé. Aujourd’hui, une bonne pratique est d’écrire un ODD (One Document Does it all) (Rahtz et Burnard 2013) Document intégralement écrit en xml qui fonctionne comme un schéma pour non seulement régir l’encodage et assurer l’homogénéité d’un projet, mais aussi produire une documentation sur les choix d’encodage. Pour aller plus loin, consulter le chapitre « Getting Started with P5 ODDs » (The Text Encoding Initiative, s. d.).↩︎. Les fichiers xml TEI peuvent ensuite être transformés à condition d’avoir quelques bases en XSLT, en Python, en R et en langages web (html, css, JavaScript etc.) pour générer des interfaces de lecture, des analyses statistiques de corpus ou encore des graphiques. Les fichiers xml TEI peuvent aussi être réexploités grâce à des protocoles plus simples, en utilisant par exemple TEI Publisher, qui propose une interface graphique pour créer des visualisations de son édition à partir des fichiers xml TEI et éventuellement de l’ODD, ou encore à l’aide de TXM (Heiden et al. 2010) pour faire des études lexicométriques.
Dans un écosystème de science ouverte et partageableQuoiqu’il soit encore naissant aujourd’hui.↩︎, l’encodage peut être repris, modifié, augmenté, permettant à d’autres projets d’exploiter les données, ou encore à un nouvel éditeur de partir d’un travail plus détaillé qu’une édition papier qui comporte un grand nombre d’ambiguïtés ou dont les strates de données intermédiaires ont disparu derrière le texte édité. Ainsi, l’édition numérique permet de passer d’un cheminement linéaire qui n’avait pour aboutissement que le texte édité, à un cheminement ouvert, où les différentes strates de l’établissement constituent des données. L’éditeur numérique peut alors se penser à la fois comme un producteur de texte et comme un producteur de données pour d’autres projets.
Le passage à un format numérique, à notre sens, n’amène pas à faire table rase du passé (Mounier 2010) ni à révolutionner les méthodologies de l’édition qui peuvent déjà être très différentes d’un courant à un autre, d’un champ à un autre (Duval 2015, 4‑9). Toutefois, cet enrichissement numérique s’accompagne d’une augmentation du temps consacré à l’annotation du texte, tâche jusqu’alors inexistante, et aujourd’hui obligatoire. Il semble alors d’autant plus important de valoriser ces données invisibles afin qu’elles puissent servir non seulement dans le cadre de l’édition et de l’interprétation du texte, mais aussi pour qu’elles aient une vie, non seulement dans le cadre de l’édition et de l’interprétation du texte, mais aussi en dehors de celles-ci. En nous basant sur les travaux que nous avons réalisés dans le cadre de notre thèse (Pinche 2021), nous exposerons ici trois cas de valorisation et d’exploitation des données numériques : l’exploitation des variantes textuelles, des données linguistiques et des données issues de la transcription graphématiqueReprésentation imitative du texte de la source qui ne tient pas compte des variantes de forme des graphèmes (Stutzmann 2011).↩︎.
Exploitation des données issues des variantes dans la tradition manuscrite
La collation des différentes variantes présentes dans les manuscrits est nécessaire à l’établissement d’une édition critique. Son but est de constituer un stemma afin d’organiser la tradition en familles de manuscrits et de hiérarchiser les témoins en fonction de leur proximité avec un original perdu. Cette méthode est née des théories allemandes de la fin du XIXe siècle et notamment des travaux de K. Lachmann (Fornaro 2011; Trovato et Reeve 2014). P. Maas (Fornaro 2011; Trovato et Reeve 2014) a fait tendre cette approche vers une étude statistique. La philologie italienne, avec G. Pasquali (Fornaro 2011; Trovato et Reeve 2014), G. Contini (1986), ou encore C. Segre (2015), s’est emparée de ces travaux pour fonder l’école néo-lachmanienne et a approfondi l’étude de la tradition manuscrite. Ces chercheurs ont en effet montré à quel point la transmission du texte dans les manuscrits pouvait être complexe à cause de la mouvance textuelle et en proposant des solutions au scepticisme de J. Bédier (1928b, 1928a, 1976) quant à la possibilité d’établir des stemmata pour les textes médiévaux (Roelli 2020 Introduction, 4).
Le standard TEI dispose de balises spécifiques pour constituer un apparat critiqueVoir les TEI Guidelines sur l’encodage des apparats critiques (2021).↩︎. L’encodage permet à la collation, devenue données, d’être exploitée au-delà de la simple visualisation de l’apparat.
Planche 7.c – Exemple d’une page d’édition critique issue de la Vie de saint Martin

Proposé par auteur le 2023-03-27
L’intégralité de la collation peut être vérifiée, aisément corrigée, voire augmentée si besoin. L’apparat peut être interrogé et parcouru. Plutôt que de faire un relevé « manuel » des variantes pour créer son stemmaÉtude qui par ailleurs est toujours extrêmement subjective puisqu’il faut sélectionner un certain nombre de variantes signifiantes qui soit traitable par l’homme.↩︎, la tâche peut être automatisée pour partie. Si une typologie des variantes a été établie au préalable dans l’apparat numérique, on peut alors générer automatiquement une base de données pour étudier statistiquement le corpus, à l’aide de langage comme R ou Python, et produire de manière semi-automatique un stemma.
Pour profiter pleinement des nouvelles possibilités d’exploration du corpus qu’offrent les technologies numériques, l’analyse peut être assistée par le package Stemmatology (Camps 2019) pour R développé par F. Cafiero et J. B. Camps (2018). La méthode proposée est basée sur les principes néo-lachmanien de généalogie textuelleCette méthode découle elle-même de la méthode lachmanienne qui s’appuie sur les erreurs communes des témoins d’une tradition pour déterminer les liens de parenté entre les différents manuscrits.↩︎. L’algorithme s’appuie sur les lieux variants communs aux différents témoins et par un jeu de comparaison distingue les leçons ayant un caractère généalogique du bruit généré par les variantes peu significatives. Une fois le tri opéréLe tri s’effectue de manière semi-automatique, dans les cas où une leçon est problématique, l’algorithme permet un choix manuel qui peut être éclairé par la connaissance de la tradition manuscrite.↩︎, des relations de parenté sont établies entre les manuscrits. Reléguer une partie du tri et de la comparaison des lieux variants à la machine revêt de nombreux avantages, d’autant plus lorsque l’on travaille avec des textes en langue vernaculaire dont les variations et les remaniements sont foisonnants d’un témoin à un autre. Cette profusion a d’ailleurs bien souvent découragé la critique textuelle moderne face au travail titanesque et parfois peu concluant que représente l’établissement des stemmata de ces œuvres« It has been argued by some modern textual critics that coincident and inevitable that the formation of a stemma is impossible and any attempt to do so is a waste of time » (Poole 1974).↩︎. L’algorithme permet, en parcourant l’ensemble des données collectéesCe qui serait extrêmement coûteux en temps et en main-d’œuvre sans une assistance computationnelle. On peut, ici, se référer aux expériences de Dom Quentin et Dom Froger qui ont commencé « à la main » de telles expériences avant d’adapter leur méthode à une pratique automatisée et assistée par l’ordinateur (Quentin 1926; Froger et al. 1968; Froger 1970).↩︎, de faire ressortir les lieux variants déterminants. Grâce à cette méthode, le processus d’établissement du stemma a pu prendre en compte 709 lieux variantsLe nombre de lieux variants sélectionnés aurait difficilement pu être étudié manuellement dans le cadre d’un travail individuel limité dans les bornes temporelles d’un doctorat.↩︎ sélectionnés dans la Vie de saint MartinSeules les variantes ayant été identifiées dans l’encodage comme étant des variantes sémantiques ont été utilisées.↩︎. Certaines leçons, évaluées par l’algorithme comme étant problématiques dans la tradition et très certainement à la racine de divergences entre deux clusters (voir figure 7.b ci-dessous), nous permettent de voir très clairement se dessiner deux branches dans la tradition (voir exemple 1), mais aussi de faire apparaître des phénomènes de contamination (voir exemple 2).
Figure 7.b – Exemple de clusters obtenus grâce à Stemmatology

Proposé par auteur le 2023-03-27
Ainsi un stemma final a été établi (voir figure 7.a ci-dessous) en accord avec les précédentes recherches sur les légendiers hagiographiques français de Paul Meyer (1906) et les hypothèses de J.J. Thompson (1993), tout en permettant aussi d’approfondir l’analyse et de révéler la position toute particulière du manuscrit F2Voir la liste des manuscrits utilisés dans la collation en contenu additionnel, tableau 7.a - Liste des manuscrits utilisé pour la collation de la Vie de saint Martin.↩︎, point de contagion entre les deux branches dans la tradition manuscriteNous remercions J. B. Camps qui nous a accompagnée tout au long de l’exploration du corpus avec Stemmatology.↩︎.
Figure 7.a – Stemma établi à partir de la collation des variantes de la Vie de saint Martin
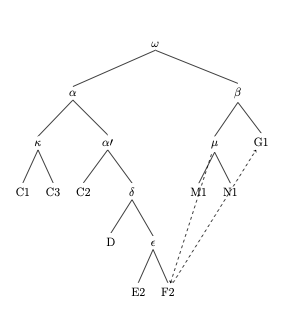
Proposé par auteur le 2023-03-27
Exemple 1
Sélection de leçons qui révèlent une configuration en deux sous-réseaux :
exemple prendre (C1, C2, C3, D, E2, F2), prendre essample de bien (G1, M1, N1)
flamber (C1, C2, C3, D, E2, F2), faire grant flambe (G1, M1, N1)
la fermeüre desfermer del huis (C1, C2, C3, D, E2), defermer huis (F2), la serrure desfremer (G1, M1, N1).
Exemple 2
Sélection de leçons qui révèlent des contaminations entre les deux sous-réseaux :
De diversitez (C1, C2, C3, D, E2), d’aversitez (F2, G1, M1, N1)
qi de Poitiers estoient (C1, C2, C3, D, E2), de Poitiers (F2, G1, M1, N1)
Cette méthode présente toutefois quelques limites. Il n’existe pas encore de liste(s) de types de variantes pour faciliter le moissonnage et surtout mettre en place un encodage homogène d’un projet à un autreDes essais de classification des variantes ont été faits par R. Wilhelm et pourraient être repris avec profit (2015).↩︎. Un tel classement permettrait également d’améliorer des outils comme Stemmatology qui pourraient alors proposer de pondérer certains types de leçons, évitant ainsi une sélection subjective d’un certain nombre de variantes parmi les plus signifiantes ou parmi celles qui proposent un texte difficile à reproduire, à corriger, ou encore une altération sémantique.
En France, les éditions critiques imprimées ne consignent que les variantes sémantiquesPar exemple, la collection Textes littéraires français de Droz ou encore la collection Champion classique “Série Moyen Âge” d’Honoré Champion.↩︎. Dans le cas des éditions de textes en langue vernaculaire, on comprend d’autant mieux ces restrictions que la variété des graphies rend impossible l’affichage de l’intégralité des variations dans la limite d’une page papier, comme le souligne F. Duval au sujet des éditions numériques et de leur rapport à la new philology :
Pour des raisons économiques, le papier est contraint de se limiter à un seul état textuel (single text editions, one text editions), qu’il soit ou non reconstruit. Grâce au “multi-fenêtrage” et à l’hypertexte, le numérique s’est imposé comme le médium approprié et indispensable à l’application des “nouvelles” théories textuelles (2017).
L’apparat numérique permet de dépasser ces limites matérielles et de transmettre une collation plus détaillée avec les variations de nombre, de genre, les variations sur les mots-outils, voire même les variations graphiquesToutefois, dans le cadre de l’édition d’un texte en ancien français une telle précision rendrait la collation extrêmement chronophage. Dans ce cas une automatisation de la tâche avec une récupération complète du texte grâce à un outil d’HTR (Handwritten Text Recognition, reconnaissance de l’écriture manuscrite) et un alignement automatique des variantes semblerait plus pertinent (voir la communication de Camps et al. (2019)).↩︎. Dans la lignée des nouvelles théories philologiques qui accordent une plus grande importance à la copie que ne le faisaient les courants de la fin du XIXe et du XXe siècle, les éditions numériques permettent de donner davantage d’importance à la matérialité du texte et à sa transmission dans la tradition manuscrite. On peut alors intégrer aisément dans la collation tout un éventail de variations pour analyser la langue des autres manuscrits et les liens que les témoins entretiennent entre eux« Grâce à des approches quantitatives et comparatives, des champs d’études s’ouvraient et les questionnaires scientifiques se renouvelaient : la linguistique diachronique ou d’états anciens en a profité, notamment en syntaxe, par l’étude de la ponctuation ou de la segmentation graphique. L’étude des microvariantes est un secteur en développement (Lepage et Milat 2008) et l’encodage toujours plus poussé des documents, notamment allographétique, promet de nombreuses découvertes » (Duval 2017).↩︎.
Dans l’édition des Seint Confessor, l’apparat critique (voir l’exemple ci-dessous) se concentre essentiellement sur les variations d’ordre sémantique au niveau lexical, sur les additions, les omissions, les inversions, mais s’intéresse aussi aux variations qui touchent les mots-outils, même quand l’impact est moindre d’un point de vue sémantique. Une analyse des variations sur les mots-outils (voir exemple) entre les deux principaux représentants de chacune des branches du stemma a révélé une modernisation de la langue.
Figure 7.c – Exemple d’encodage de l’apparat critique issu de l’édition numérique de la Vie de saint Martin

Proposé par auteur le 2023-03-27
Exemple de remplacement des mots-outils entre les témoins C1 et G1 :
Remplacement de tresqu(e) par jusqu(e) (10 fois)
Remplacement de ensamble (o) par avec (21 fois)
Remplacement de la forme étymologique er(en)t par la forme moderne estoi(en)t (20 fois)
Remplacement de l’expression avoit non par estoit apelez (6 fois)
Enfin, la collation numérique a permis de dépasser les hypothèses de J.J. Thompson qui fut le premier à étudier les Seint Confessor et à en comprendre le fonctionnement (1993). En effet, l’approche quantitative par compte de mots a prouvé que G1, principal représentant de la deuxième branche, ne donnait pas une version abrégée du recueil, mais une version remaniée. En effet, il supposait que la version de C1, principal représentant de la première branche, était une version longue du recueil des Seint Confessor, tandis que G1 en proposait une version courte (1993, 45‑56). Toutefois, si on compare les deux recueils au niveau des unités textuelles, le nombre de mots utilisés entre les deux versions de la Vie de saint Martin révèle pour G1 une diminution de seulement 2 %. L’analyse plus fine des lieux variants montre que les deux témoins proposent deux versions différentes du texte qui pourraient mériter une édition synoptique, car presque 45 % du texte se trouve modifié entre les deux rédactions. La Vie de saint Martin possède un peu moins de endroits où les deux manuscrits proposent des leçons divergentes. Environ 27 % des modifications sont constituées par des omissions et 52 % par des variations sémantiques (Pinche 2021, 120‑23).
Figure 7.d – Étude de la répartition des types de variantes à partir de la collation de la Vie de saint Martin
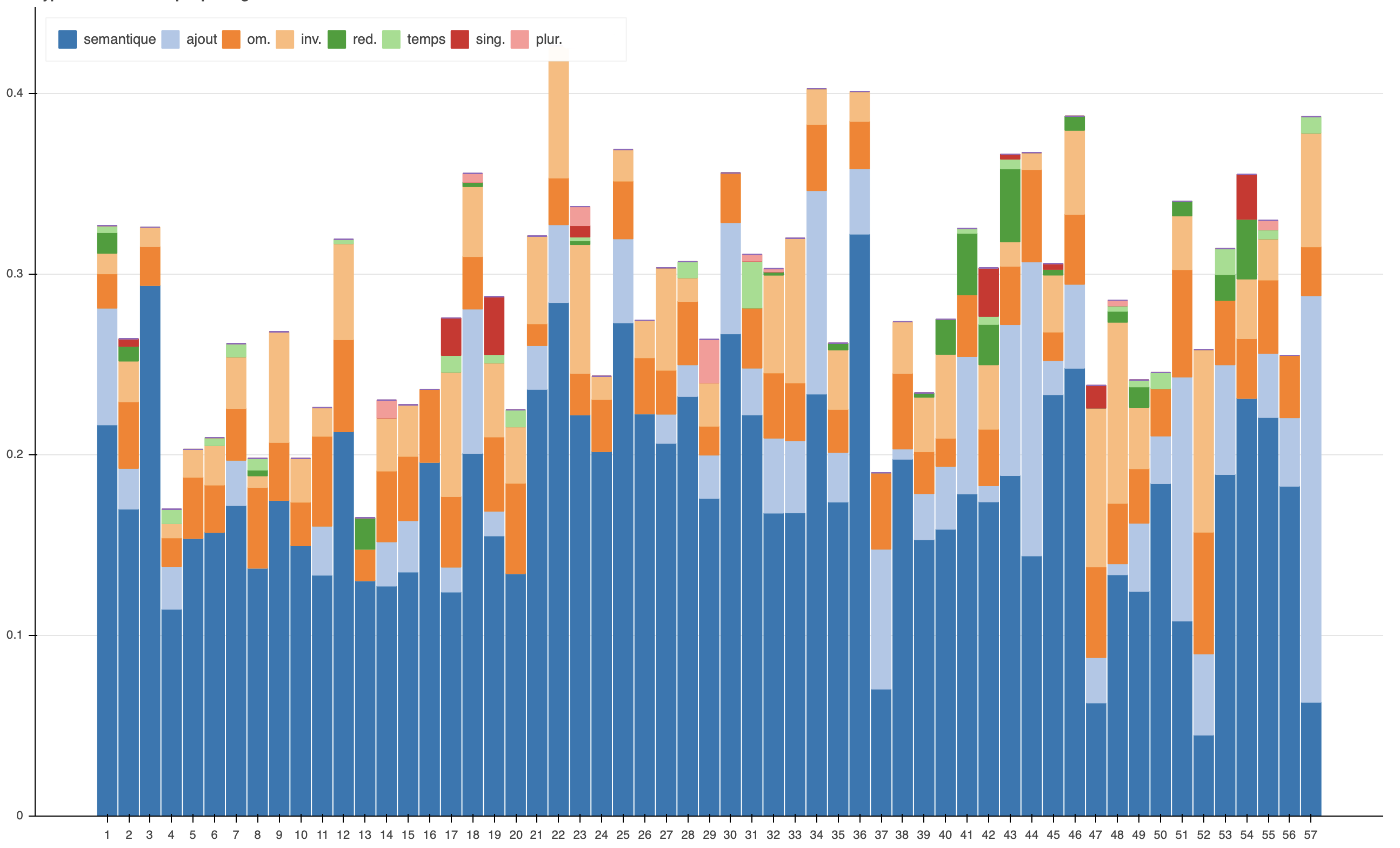
Proposé par auteur le 2023-03-27
Grâce à l’adoption des technologies numériques, certains projets comme le projet Hyperdonat ont expérimenté de nouvelles voies en proposant de parcourir la tradition manuscrite à travers une interface de comparaison des témoins, mais aussi une interface de reconstitution de « virtual witnesses » à partir des témoins existants de la traditionLe projet, encore expérimental et malheureusement inachevé, propose la mise en place d’une matrice d’apparat assez complexe à partir de la collation de toutes les variantes des témoins selon la typologie suivante : semantic, graphic, layout, structure. L’ensemble des leçons de chacun des témoins s’appuie sur le texte établi dans les éditions de Paul Wessner, puis les leçons de chacun des témoins sont rassemblées pour former une matrice de variantes qui permet la mise en place de l’édition critique, de l’interface de comparaison des témoins ou encore de créations de « virtual witnesses » (Pinche et al. 2016).↩︎. Le projet d’édition de Guiron le courtois mérite également toute notre attention. Le texte numérique est établi branche par branche avec des éditions intermédiaires pour chacune d’entre elles afin d’établir un texte critique qui garde une trace de la surface linguistique pour chaque branche de la tradition. La réunion des différentes éditions permettra à terme de retracer le stemma dans toute sa complexité et petit à petit d’arriver à l’édition critique finale de l’œuvre tout en suivant les innovations au fil de la transmission du texte (Trachsler et Leonardi 2015).
Dans le cadre de nos travaux, les données de la collation ont pu être exploitées en dehors de l’apparat critique et même dans un autre but que l’établissement du stemma. Elles ont permis de constituer une étude chiffrée des divergences entre deux versions du texte et de consolider le commentaire de l’œuvre. Là où ces informations seraient restées cachées dans les brouillons de l’éditeur, grâce à l’édition numérique, elles ont pu être consignées dans les fichiers xml TEI, archivées et réutilisées.
Exploitation des données linguistiques
Le texte établi dans l’édition des Seint Confessor ne propose pas de lissage linguistique et dans la mesure du possible, sauf erreur évidente du scribe, livre le texte du manuscrit de baseManuscrit C1.↩︎ avec le moins de correction possible. Si cette méthode est parfois contestée, notamment par les néo-lachmaniens, car elle ne propose pas de reconstruire le texte le plus proche possible de l’archétype et est parfois ressentie comme un refus d’éditer, comme le constate E. Pierazzo (2015), nous avons préféré proposer un texte qui soit le témoignage d’un document historique avec ses irrégularités linguistiques dans la lignée des propos de C. Marchello Nizia :
Notre but est de procurer une version du texte sous une forme la plus fidèle possible à la version singulière transmise par le manuscrit de base choisi. C’est à cette condition que nous pouvons accéder à un témoin effectif, à une version précise du roman, telle qu’elle a été lue, écoutée, recopiée sans doute au XIIIe siècle : à ce que l’on pourrait nommer une version “usagée” du texte imparfaite peut-être, mais transmise par un copiste et reçue par des lecteurs-auditeurs. Il s’agit d’un choix bien pesé, et sans doute influencé par le fait que les médiévistes à l’origine du projet étaient des linguistes, et tout spécialement des linguistes diachroniciens qui ne pouvaient concevoir l’accès aux changements linguistiques et à l’évolution des langues autrement qu’à travers l’exploration de témoins indiscutables, c’est-à-dire d’énoncés ayant été réellement performés dans un échange précis (2019, 59).
Ce choix a permis une analyse linguistique et statistique d’un
corpus « de terrain », ainsi que d’obtenir un relevé exhaustif des
phénomènes à étudier. En regard de l’étendue de notre projet
numérique, 123 000 tokensDans le cadre de notre étude, un token est
un élément du texte obtenu suite à la « tokenisation » qui peut aussi
bien être un mot qu’un signe de ponctuation.↩︎, la tâche a été
automatisée. Un étiquetage automatique des lemmes et de la
morphosyntaxe a été mis en place à l’aide d’un annotateur qui
fonctionne à partir d’algorithmes de deep learning
(apprentissage profond) qui ne s’appuient pas sur un dictionnaire ou
un ensemble de règles prédéfinies en raison des variations propres au
français médiéval. L’annotateur Pie
(Manjavacas et
al. 2019) pour l’ancien français fonctionne par apprentissage
machine à partir d’un corpus d’entraînement annotéPrincipes de Machine learning supervisé.↩︎
et associe à chaque mot un lemme, un « POS » (Part of Speech)
et une analyse morphosyntaxique (Pinche 2019). Dans un
deuxième temps, l’annotation a été vérifiée grâce à l’interface de
post‑correction de Pyrrha
(Clérice et al.
2018) disponible en ligne. L’interface a permis de générer pour
chaque texte un fichier xml
TEI
annotéChaque mot est englobé dans une balise <w>. Le
lemme est indiqué grâce à l’attribut @lemma et
l’étiquetage morphologique est quant à lui consigné dans les attributs
@pos et @msd, suivant les préconisations des
« P5 : Guidelines for Electronic Text Encoding and Interchange », 31
août 2021, « Simple
Analytic Mechanisms » (2021), voir figure 7.f.↩︎.
L’annotation linguistique a servi de base pour explorer le corpus. Elle a permis, par exemple, d’étudier la quantité de termes touchés par un phénomène dialectal et de voir que certains phénomènes étaient généralisésPar exemple, la réduction picarde de -iee en -ie pour les participes féminins.↩︎, tandis que d’autres étaient en réalité assez marginaux. Bien que Li Seint Confessor soient identifiés comme appartenant à la sphère linguistique des dialectes du Nord-Est, où le son [ọ] est généralement noté <iau> ou <au>, les formes en <iau> n’apparaissent qu’en de très rares endroits, au bénéfice de la forme en <eau>, identifiée comme francienneCf. Gossen §12, Pope §501, §1320 xvii et §1322 ix.↩︎. Par exemple pour le terme « beau », on trouve 7 occurrences de la graphie « biau(s) », contre 117 de la graphie « beau(s) ». Ainsi, l’étude de la scripta d’un texte nous montre qu’un manuscrit offre toujours à son lectorat un état de la langue complexe issu de strates linguistiques diverses, mais aussi que notre connaissance des corpus médiévaux est encore à approfondir. Une annotation linguistique systématique des textes édités permettrait alors de mettre à jour les grammaires et les encyclopédies linguistiques (Dees et al. 1987) et de poursuivre l’entreprise du Nouveau Corpus d’Amsterdam de Pierre Kunstmann et Achim Stein (2007).
Toutes les données linguistiques du corpus sont maintenant réutilisables, notamment par les linguistes qui voudraient approfondir son exploration. La génération automatisée de ces données amène à imaginer des élargissements. En utilisant les mêmes technologies, l’étude linguistique pourrait être étendue aux autres témoins de la tradition pour comparer les résultats et essayer de repérer les traits récurrents d’une copie à une autre, peut-être même, ceux propres à l’auteur. Une autre étude à l’échelle d’un manuscrit complet permettrait, quant à elle, de comparer les différents textes et peut-être de faire surgir les traits liés cette fois au scribe, le problème restant dans les deux cas l’acquisition du texte pour étendre l’étude.
L’annotation linguistique a également pu être réutilisée en dehors de ce contexte. Elle a permis de faire quelques prospections lexicométriques, en utilisant l’indice de spécificité de Lafon (1980) et TF-IDFLa méthode permet de confronter la fréquence d’un terme dans un texte à sa fréquence dans un corpus plus large, (Sparck Jones 1972, 11‑21).↩︎ (Term frequency-inverse document frequency) afin de déceler des thèmes récurrents et spécifiques à notre texte pour faciliter l’analyse le recueil. Grâce aux études lexicométriques, on remarque la prégnance de nouveaux termes dans les trois dernières Vies des Seint Confessor tels que frereVie de saint Benoît : Score TF-IDF : 0.106 — spécificité de Lafon 90,1. Vie de saint Jérôme : score TF-IDF : 0.14 — spécificité de Lafon 15,4.↩︎, moineLe terme ressort tout particulièrement dans la Vie de saint Benoît avec un score TF-IDF de 0,073 et Lafon de 47,4.↩︎ et abeieVie de saint Benoît : Score TF-IDF : 0.069 — spécificité de Lafon 39,2. Vie de saint Jérôme : score TF-IDF : 0.04 — spécificité de Lafon 3,6.↩︎ dans les Vies de saint Benoît et de saint Jérôme où l’accent est mis sur la vie en communauté. Dans la Vie de saint Alexis, on voit se dégager l’idée de renoncement au monde à travers le terme povreScore TF-IDF : 0.079 — spécificité de Lafon 8,5.↩︎. Ces termes témoignent d’une présence de plus en plus forte dans le recueil d’une idéologie de l’ascèse (voir tableaux ci-dessous).
Tableau 7.b – Sélection des scores TF-IDF les plus hauts pour les Vies de saint Benoît, saint Jérôme et saint Alexis
| Vie de saint Benoît | Vie de saint Jérôme | Vie de saint Alexis | |||
|---|---|---|---|---|---|
| Terme | Score | Lemme | Score | Lemmes | Score |
| saint | 0.312 | asne | 0.262 | saint | 0.240 |
| frere | 0.106 | lïon | 0.225 | nostre | 0.187 |
| moine1 | 0.073 | saint | 0.198 | emperëor | 0.125 |
| abeie | 0.069 | chamoil | 0.166 | cité | 0.103 |
| nostre | 0.067 | frere | 0.140 | fil2 | 0.101 |
| chose | 0.065 | nostre | 0.119 | vie1 | 0.096 |
| oraison | 0.062 | pasture1 | 0.097 | maison | 0.083 |
| eglise | 0.052 | marchëant | 0.094 | pere | 0.080 |
| avenir | 0.049 | creche | 0.073 | povre | 0.079 |
| tu | 0.046 | chose | 0.071 | tu | 0.075 |
| foie2 | 0.038 | eglise | 0.063 | chartre1 | 0.067 |
| maniere | 0.035 | busche | 0.062 | mïemement | 0.067 |
| comencier | 0.035 | ebrieu | 0.059 | o4 | 0.065 |
| lieu | 0.034 | ues | 0.053 | feme | 0.063 |
| dïable | 0.034 | caldeu | 0.051 | voiz | 0.059 |
| tantost | 0.033 | latin | 0.050 | tresque1 | 0.059 |
| parole | 0.033 | comander | 0.050 | chose | 0.057 |
| ensemble | 0.033 | porte1 | 0.049 | jovencel | 0.057 |
| prestre | 0.033 | clochier2 | 0.046 | ainsi | 0.055 |
Proposé par auteur le 2023-03-27
Tableau 7.c – Sélection des scores les plus hauts pour l’indice de spécificité de Lafon dans les Vies de saint Benoît, saint Jérôme et saint Alexis
| Vie de saint Benoît | Vie de saint Jérôme | Vie de saint Alexis | |||
|---|---|---|---|---|---|
| Terme | Spécificité | Lemme | Spécificité | Lemmes | Spécificité |
| Beneoit | Infini | Jerome | 81,99 | Alexis | 73,99 |
| saint | 181,03 | asne | 36,98 | Eufamianus | 60,92 |
| frere | 90,11 | lïon | 31,66 | que2 | 36,97 |
| orison | 57,99 | chamoil | 20,97 | saint | 18 |
| moine1 | 47,43 | que2 | 17,44 | nostre | 17,51 |
| abeie | 39,27 | frere | 15,47 | Rome | 14,89 |
| il | 38,18 | Bethleem | 14,88 | et | 11,41 |
| si | 35,15 | saint | 13,82 | vie1 | 9,81 |
| ome | 32,16 | pasture1 | 12,33 | maison | 9,32 |
| Maurus | 29,54 | marchëant | 10,58 | emperëor | 9,1 |
| xfoie2 | 20,39 | si | 9,88 | povre | 8,57 |
| avenir | 18,32 | il | 9,77 | cité | 8,3 |
| un | 17,82 | nostre | 8,34 | si | 8,25 |
| Zalla | 17,29 | creche | 7,65 | seignor | 7,93 |
| chose | 16,86 | Rome | 7,36 | maisniee | 7,33 |
| eglise | 15,84 | come1 | 7,03 | mïemement | 7,24 |
| nostre | 15,8 | latin | 6,11 | fil2 | 6,91 |
| costume | 14,33 | busche | 5,99 | voiz | 6,81 |
| Theoprobus | 12,86 | ues | 5,86 | pere | 6,5 |
| roche3 | 11,8 | ebrieu | 5,71 | chartre1 | 6,46 |
Proposé par auteur le 2023-03-27
Toutefois, le travail de lemmatisation et surtout de correction des données, si l’on veut atteindre une qualité acceptable pour une analyse linguistique sur des graphies aussi peu stables que celles de l’ancien français, est un travail extrêmement longSur un corpus identique au notre (123 000 tokens), à un rythme de 200 mots par heure, cela représente un peu moins de quatre-vingt-dix jours de sept heures de travail uniquement appliqués à cette tâche.↩︎. Il demande beaucoup de précision et peut se révéler fort peu gratifiantEn cela, des outils de post-correction comme Pyrrha sont d’une grande aide.↩︎, même s’il est fondamental pour la connaissance de notre corpus. Dans notre cas, ce travail n’est pas resté enfermé dans les limites de l’édition. Ces efforts ont permis de constituer, pour la lemmatisation de textes en langue d’oïl, un corpus dit « gold« Gold standard is a dataset which has been annotated (either manually or automatically) and then manually corrected » (PORT, University of London, « NLP and Named Entry Recognition »).↩︎ ». Ce corpus s’appuie sur deux standards : l’étiquetage morphosyntaxique et la constitution de ses catégories s’appuient sur le référentiel étendu de Cattex 2009 (Guillot et al. 2013). Les lemmes ont été établis à partir du dictionnaire Tobler-Lommatzsch (1952) et adaptés dans les cas où les entrées n’étaient pas homogènesVoir la documentation, « lemmes retenus de Tobler Lommatzsch ».↩︎. Le respect de ces standards a permis aux données de s’intégrer dans un ensemble de corpus afin de créer un modèle général pour la lemmatisation de l’ancien français et d’entraîner le modèle d’annotation Deucalion développé à l’École nationale des chartes (Clérice et al. 2020). Aujourd’hui le modèle atteint un niveau de fiabilité de 95 % pour les lemmes et les POS et de 90 % pour l’annotation morphosyntaxiqueSeuls 30 % des données du modèle possèdent cette information qui, par ailleurs, est plus complexe à traiter automatiquement en raison de sa forte disparité.↩︎.
Ainsi, la lente accumulation des données linguistiques n’a pas disparu sous le commentaire linguistique, mais au contraire a pu être réutilisée pour le commentaire de l’œuvre. Les données sont aussi sorties de l’édition et ont déjà démontré leur utilité en aidant à créer un modèle de lemmatisation qui pourra servir à automatiser la tâche d’annotation linguistique pour d’autres corpus.
Figure 7.e – Schéma de la réutilisation des données issues de la collation dans l’édition numérique

Proposé par auteur le 2023-03-27
Exploitation des données issues de la transcription graphématique
Afin de respecter le texte comme document, les fichiers xml TEI sources qui ont servi à l’établissement du texte conservent en leur sein toutes les données de mise en page, ainsi qu’une transcription graphématique du manuscrit de base. Consigner toutes ces informations a permis de proposer aux lectorats plusieurs vues du texte (voir les deux figures ci-dessous), ce qui permet de vérifier les informations d’établissement du texte et de faciliter le retour à la source pour tout lecteur non expert en paléographie.
Figure 7.i – Transcription graphématique de la Vie de saint Martin, d’après le manuscrit fr. 412 de la Bnf, fol. 103r
Proposé par auteur le 2023-03-27
Figure 7.j – Transcription normalisée de la Vie de saint Martin, d’après le manuscrit fr. 412 de la Bnf, fol. 103r
Proposé par auteur le 2023-03-27
La représentation imitative du texte (voir figure 7.i) renferme des indications de mise en page qui peuvent aider à comprendre l’origine des erreurs de copiePar exemple, on lit dans C1 au folio 130d, dans la Vie de saint Gilles : « Qant li rois vit qe la chose (estoit) estoit veraie ». L’erreur par dittographie du scribe peut s’expliquer par un saut de ligne entre les deux estoit.↩︎. Les abréviations présentes dans le document source sont également signalées, ainsi que la ponctuation originale.
Figure 7.h – Exemple d’encodage des développements d’abréviations
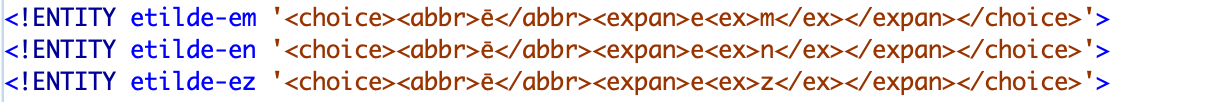
Proposé par auteur le 2023-03-27
Ces informations ne sont pas uniquement destinées à permettre un affichage imitatif du texte du manuscrit de base, mais pourront être réexploitées par des linguistes pour des études sur des phénomènes restreints, à l’instar de l’étude sur la ponctuation menée par A. Lavrentiev (2016).
Cette méthode a permis d’établir un rapport précis des modifications opérées. Par exemple, le corpus des Seint Confessor comporte 6300 abréviations sur un corpus de 67 folios à deux colonnes. L’utilisation de la note tironienne ⁊ représente 75 % des abréviations et 92 % des abréviations sont réparties entre sept signes différents. Outre le fait que ces informations permettent d’accompagner l’édition d’annexes précises sur la manière dont les abréviations ont été développées dans le corpus (voir tableau ci-dessous), ces statistiques montrent que le texte en langue vernaculaire peut être aisément lu sans une connaissance savante du système abréviatif.
Tableau 7.d – Table des abréviations et de leurs développements dans le recueil des Seint Confessor
| Abr. | dév. | Nb | Termes |
|---|---|---|---|
| 7 | et | 4764 | et |
| ꝑ | par | 275 | aparut, departement, departi, departie, departies, departir, departir, departirent, departirent, departiroit, departisist, departisist, departoit, espartirent, par, pardon, parfete, parla, parler, parlions, parloit, parlé, parmenable, parmi, parole, paroles, pars, part, partie, parties, partir, partout, parvenir, parvenue, parz, parler, partie, partirent, partout |
| 9 | con | 247 | aconplir, confessor, congié, conmanda, conmandas, conmandast, conmande, conmandement, conmandemenz, conmander, conmanderent, conmanderoit, conmandez, conmandoit, conmandé, conmant, conmanz, conme, conmence, conmencement, conmencier, conmencierent, conmencié, conment, conmença, conmençames, conmençast, conmunement, conneües, conneüssent, connissoit, connoistre, conpagnie, conpaignons, conselle, consomee, conterai, contre, contree, controverei, conté, conurent, convient, encontre, raconte |
| ē | en | 194 | aeuroient, alerent, amerent, amoient, aoroient, argent, arrestoient, assemblerent, assiduelment, assistrent, avoient, baptizierent, bien, biens, boivent, ceens, cenz, chastement, citoien, comencierent, comença, condenpnabitur, conmencierent, conment, conurent, covient, croient, deguerpeïssent, demanderent, dementieres, demorerent, descendoit, descendre, desirroient, diemence, distrent, doivent, dolenz, donerent, empense, emporteroient, en, enorter, ensanglente, entendi, entendoient, entendoit, ententive, entiegent, entrefirent, envoierent, erent, esgardoient, esmurent, estoient, fesoient, firent, foïssent, furent, fussent, genz, governement, griement, habitent, hantent, indulgense, jovenceaus, jovencel, lendemein, longement, mandement, meintient, mendiz, mengier, mengoit, menroient, mistrent, moveroient, noient, oceïssent, ocistrent, Orient, paien, paiens, partirent, pensoient, peüssent, porpensa, portoient, prendoit, prendre, prendroient, prensignast, prensigniez, pristrent, proierent, puent, reclaiment, rendez, rendi, repristrent, respondirent, retiegnent, retrestrent, revellierent, rieng, riens,, siens, sovent, tenpore, tesmoignent, tesmoigneroient, trenchier, trentiesme, trestrent, troverent, veillierent, venoient, vent, ventreil, venz, veoient, vindrent, virent, voelent, voient, volent, volentiers |
| ĩ | in | 120 | ainz, ausint, aussint, avint, Benjamin, ceint, certeinnement, compleindre, destreins, einsint, einz, estreinz, larrecin, loing, Martin, Martins, mein, meins, meintenant, meintenir, meintenissent, meinz, peinnes, pleins, revint, seint, seinte, seintismes, seinz, tesmoing, venins, ving, vint, voisins |
| ō | on | 84 | adonc, adont, anoncierent, avons, barons, beneïçon, bons, compaignon, compaignons, condenpnabitur, confusïon, conmença, conpaignie, conpaignie, conseil, conter, contes, conté, devotion, dont, dragon, environnee, Jethron, meson, mesons, mon, monde, mons, monsigneur, montaigne, Noiron, non, noncierent, nonmee, nonmé, ont, orissons, oroisons, parfondece, pissonniaus, proions, puissons, raconte, raconter, raconterei, racontes, resoignons, respondi, respondoit, respons, son, sont, temptation, translation, trencherons, vision |
| ꝑ | per | 72 | apercevoir, apercevoit, aperceü, aperçut, apertement, desesperance, empereor, empereors, emperere, empereres, esperit, esperiz, pere, peres |
| ā | an | 59 | anssamblé, avant, creance, demanda, demandai, demorance, devant, doutance, enfant, ensanble, estrange, France, grant, marcheanz, meintenant, portanz, preecant, ramembrance, repentanz, sanblance, sanz, semblant, serjant, tant, tramblant |
Proposé par auteur le 2023-03-27
Ainsi les fichiers xml TEI, qui peuvent être enrichis de liens vers des reproductions de manuscrits, possèdent non seulement des vertus pédagogiques, mais permettent aussi la mise au point d’une transcription précise dont la production s’avère d’une grande utilité pour la connaissance du texte.
Ces données peuvent également être réutilisées dans un écosystème numérique plus large, notamment pour l’entraînement d’algorithmes de reconnaissance automatique de texte (HTR)Entraîner soi-même un modèle d’HTR demande d’être capable de lancer quelques commandes en Python. Aujourd’hui des services permettent de le faire à l’aide d’une interface graphique, comme eScriptorium (Kiessling et al. 2019) qui donne librement accès aux modèles entraînés ou encore Transkribus qui en revanche est propriétaire des modèles.↩︎.
Figure 7.k – Schéma de la réutilisation des données de transcription dans l’édition numérique
Proposé par auteur le 2023-03-27
L’encodage en xml TEI des fichiers de notre projet en consignant les abréviations du manuscrit, les sauts de ligne, la mise en page des colonnes et des folios a permis de fournir un set de données pour entraîner en 2019 un modèle d’HTRMalheureusement notre travail de thèse n’a pas pu bénéficier d’une aide à la transcription via l’utilisation de l’HTR dès son début. Le travail ayant été entamé en 2015, les modèles et les données librement disponibles pour les manuscrits médiévaux (nous avions surtout testé Kraken pour pouvoir entraîner nos propres modèles) ne permettaient pas encore d’obtenir des données d’assez bonne qualité pour être intégrées dans la chaîne de production du texte.↩︎ (voir figure 7.k ci-dessus) afin de produire une transcription automatisée de l’ensemble du manuscrit fr. 412 de la BnF, et d’étudier la composition du légendier complet grâce à un protocole allant de l’acquisition du texte jusqu’à l’analyse stylométrique (Pinche et al. 2019). Grâce à ce protocole, nous avons analysé la composition du manuscrit et retrouvé des sous-collections hagiographiques cohérentes avec les hypothèses de Paul Meyer selon lesquelles les légendiers sont le fruit d’assemblage de compilations successives (1906), laissant ainsi penser que certaines vies pouvaient être du même auteur et fonctionner, à l’instar des Seint Confessor, comme des ensembles cohérents.
Aujourd’hui, l’apprentissage machine a fait beaucoup de progrès et des volontés de partage de données pour l’HTR voient le jour comme le projet HTR-united. Il est important que les éditeurs numériques trouvent leur place dans un environnement scientifique où il est fort probable que l’acquisition automatique de texte prendra de plus en plus de place. Les transcriptions des Seint Confessor ont servi de base à la constitution d’un ensemble de données d’entraînement, disponible sur le dépôt Github Cremma-medieval, en vue de créer un modèle HTR plus général pour les manuscrits littéraires des XIIe et XIIIe siècles (Pinche et Clérice 2021) et ont permis de constituer un modèle d’HTR (Bicerin 1.0.1) avec des scores de 95,49 % d’accuracy sur un jeu de données composé de huit manuscrits différentsCe modèle sert déjà à d’autres projets pour accélérer le processus d’acquisition textuelle, nous pouvons citer ici le projet genevois en cours : Canoniser les Sept Sages.↩︎. L’apparition de ces technologies soulève de nouveaux enjeux et met en question la place de l’éditeur dans la chaîne d’acquisition textuelle qui pourrait être de plus en plus automatisée de l’acquisition à la visualisation du texte (Chagué et Chiffoleau 2021). Des réflexions ont également été menées par J. B. Camps, L. Ing et E. Spadini lors de la conférence Digital Humanities en 2019 sur une chaîne de production automatisée allant de l’acquisition automatique du texte jusqu’à l’alignement des témoins et la classification de leurs lieux variants (2019).
Il est donc, à notre avis, important que les compétences éditoriales soient mises au service de la confection de transcriptions pour les données d’entraînement de l’HTR et que, pour en assurer la qualité, commencent à émerger parmi eux des groupes de réflexion sur les nouvelles problématiques de transcription afin de créer les données textuelles les plus qualitatives possibles, mais aussi les plus adaptées à l’apprentissage machine. De nouveaux enjeux apparaissent, comme par exemple, l’homogénéisation et le choix des caractères spéciauxVoir à ce sujet le projet MUFI : The Medieval Unicode Font Initiative.↩︎. Ces questionnements devraient aboutir pour une grande partie à une explicitation et une homogénéisation des méthodologies déjà décrites par certains guides d’éditions imprimées (Bourgain et Vielliard 2001, 2018; Vielliard et Guyotjeannin 2001; Lepage 2001). L’établissement de transcriptions pour des corpus numériques se révèle un véritable champ scientifique en chantier, qui, loin d’être accessoire, est très complémentaire d’études de qualité, car, de fait, la composition de corpus numériques qui puissent être compatibles entre eux nous force à expliciter la question de la segmentation des mots, des ajouts de signes diacritiques, du lien entre le texte et l’objetPour aller plus loin, voir les travaux de mise en place d’une ontologie pour la description des documents du projet SegmOnto, Gabay et al. (2021).↩︎.
Conclusion
L’édition numérique permet de nous ramener à la source et de proposer des descriptions toujours plus complexes et fournies. L’établissement d’un texte numérique, contrairement à certaines idées reçues, permet rarement de gagner du tempsCependant les améliorations des technologies de transcription et d’annotation automatiques nous permettent d’espérer que le temps consacré à l’acquisition textuelle et à l’annotation linguistique devrait se voir réduit.↩︎, mais permet de faire vivre des données patiemment collectées en dehors de l’édition, là où elles demeurent souvent invisibles dans les éditions imprimées.
Toutefois, n’oublions pas les avertissements d’E. Pierazzo (2015) et P. Robinson, l’édition numérique ne doit pas se tourner uniquement du côté de l’édition documentaire et d’une description sans fin de la source, ce qui pourrait être perçu comme un refus d’éditer et amènerait à proposer des projets impossibles à terminer (Pierazzo (eds) 2016; Robinson 2003, 2013). Il est important de continuer à proposer un texte édité à diffuser à une communauté de lecteurs et lectrices, chercheurs et chercheuses comme non spécialistes. L’édition numérique par sa modularité nous offre la possibilité de concilier en son sein une approche du texte comme document et comme œuvre et les éditeurs doivent se saisir de cette opportunité« One cannot know the work without the documents — equally, one cannot understand the documents without a comprehension of the work they instance. From this, a principle appears : a scholarly edition must, so far as it can, illuminate both aspects of the text, both text-as-work and text-as-document. Traditional print editions have focused more on the first. An evident advantage of digital editions is that they might redress this balance, by including much richer materials for the study of text-as-document than can be achieved in the print medium » (Robinson 2013, 123).↩︎.
La production numérique pousse sans cesse le chercheur ou la chercheuse en dehors de son texte. L’édition numérique le projette vers un au-delà du but visé, elle devient un simple point de départ de recherches qui la dépasse.
Figure 7.l – Schéma de la réutilisation des données dans le cadre de l’édition numérique des Seint Confessor
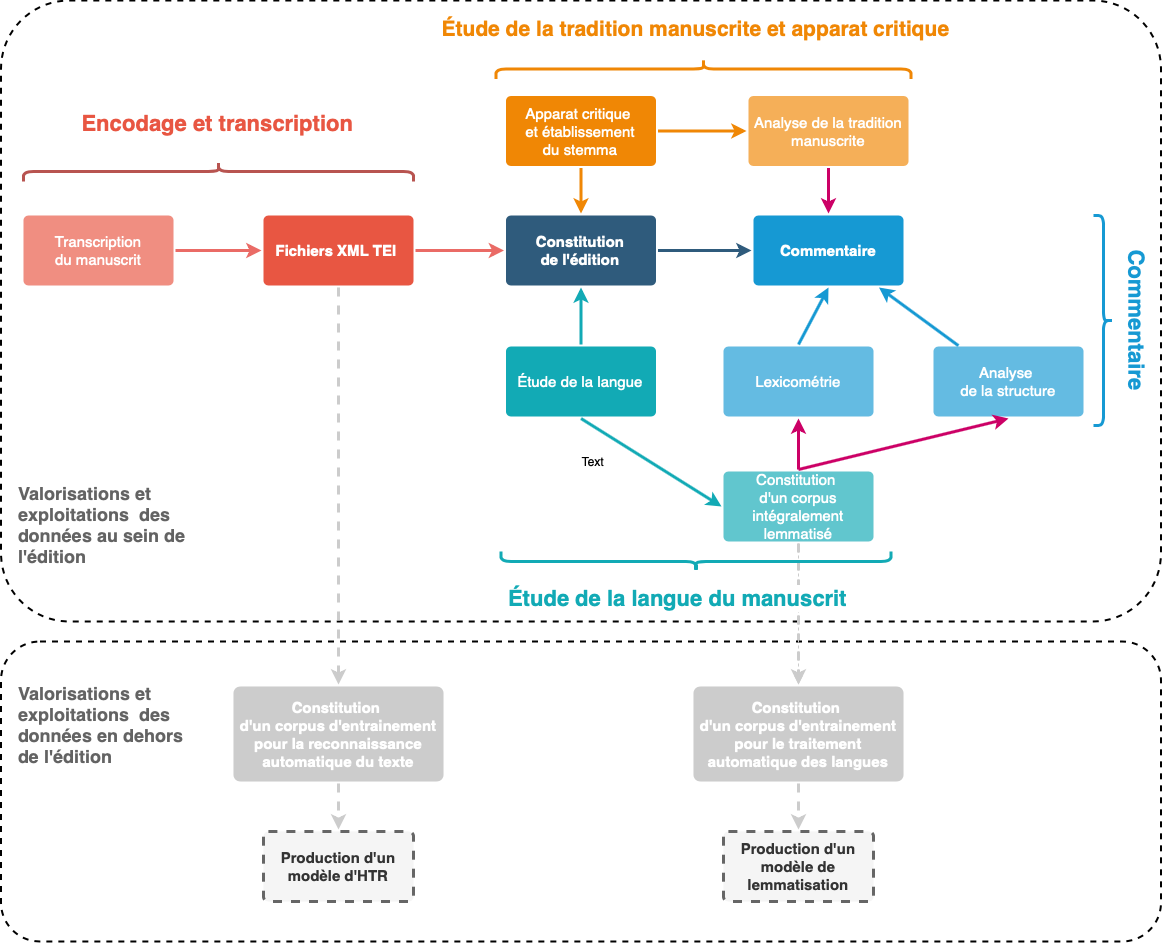
Proposé par auteur le 2023-03-27
L’édition n’est plus qu’une des productions possibles du travail sur le texte. Les corpus numériques nous amènent à passer d’une pratique individuelle qui a pour but de produire un objet fini, qui n’a besoin que d’être compris par quelqu’un d’autre, vers la production de données « en réseau » qui pourront à terme rejoindre, en-dehors de l’édition, des données produites par d’autres projets, ou être réexploitées dans un autre cadre que l’objectif pour lequel elles ont été crées. Ainsi l’éditeur numérique, à notre avis, a pour rôle aujourd’hui d’ouvrir le texte édité à d’autres usages, et doit en cela peut-être modifier ses habitudes pour passer de la production d’un texte clos sur lui-même à la modélisation de donnéesLes données ne sont pas un acquis naturel, elles sont une construction scientifique dont la qualité est primordiale pour assurer celles des analyses qui les utiliseront, « Data are capta, taken not given, constructed as an interpretation of the phenomenal world, not inherent in it » (Drucker 2011).↩︎ à partager.
La pratique des outils numériques amène à devoir tout expliciter et à interroger ses propres pratiques, car elle demande une grande rigueur et surtout de proposer une méthode reproductible. Il devient donc urgent d’essayer d’homogénéiser la constitution des corpus, la modélisation des données et d’intégrer dans nos pratiques des standards existants. Cependant, cette démarche est encore difficile en l’absence de préconisations ou d’un guide semblables à ceux de l’édition traditionnelle. Ceux-ci seraient, certes, d’autant plus complexes à mettre en place qu’ils s’adressent à un champ où les technologies évoluent rapidement.
Enfin, la valorisation des données numériques de l’édition n’est pas aisée, car il faut les rendre accessibles pour qu’elles trouvent un lectorat capable de les réexploiter. Toutefois, on peut noter l’émergence de quelques habitudes de mise à disposition avec des dépôts sur Github, la création de DOI (Digital Object Identifier), notamment via Zenodo, ou encore la mise en place de dépôts par des institutions comme Huma-Num avec GitLabPlateforme de partage de données.↩︎ et NakalaService de publication, partage et valorisation des données scientifiques.↩︎. Il est également primordial de prendre conscience de l’importance des standards pour assurer la pérennité du travail accompli et la citabilité de son édition et de ses données connexesVoir les principes de citation de DTS (Distributed Text Services) (Almas et al. 2021).↩︎ pour en assurer la réutilisation selon les critères définis par M. Dacos et P. Mounier (2010).
Références
Accéder à cette bibliographie sur Zotero
Contenus additionnels
Planche 7.a – Exemple de texte issu de la reproduction Gallica du manuscrit fr. 412 de la Bnf, fol. 103r

Proposé par auteur le 2023-03-27
Tableau 7.a – Liste des manuscrits utilisés pour la collation de la Vie de saint Martin
| C1 | Paris | Bibliothèque nationale de France, Manuscrits, fr. 412, 1285 |
| C2 | Paris | Bibliothèque nationale de France, Manuscrits, fr. 411, xive s. |
| C3 | London | British Library, Royal 20.D.VI, milieu du xiiie s. |
| D | Paris | Bibliothèque nationale de France, Manuscrits, fr. 17 229, xiiie s. |
| E2 | Genève | Bibliothèque de Genève, Comites Latentes 102, début du xive s. |
| F2 | Paris | Bibliothèque nationale de France, Manuscrits, fr. 23 117, xiiie s. |
| G1 | Bruxelles | Bibliothèque royale, 9225, 1 moitié du xive s. |
| M1 | Paris | Bibliothèque nationale de France, Manuscrits, fr. 23 112, xiiie s. |
| N1 | Paris | Bibliothèque nationale de France, Manuscrits, fr. 422, fin du xiiie s. |
Proposé par auteur le 2023-03-27
Figure 7.f – Exemple d’encodage des annotations linguistiques

Proposé par auteur le 2023-03-27
Stylometry for Noisy Medieval Data : Evaluating Paul Meyer’s Hagiographic Hypothesis
Proposé par auteur le 2023-03-27
Ariane Pinche
Docteure en langue et littérature médiévales et postdoctorante à l’École nationale des chartes. Elle s’intéresse tout particulièrement à l’édition numérique et a remporté le prix Fortier de la meilleure communication jeune chercheur lors de la conférence Digital Humanities 2019 à Utrecht avec ses deux collègues J.B.Camps et T.Clérice pour la communication Stylometry for Noisy Medieval Data : Evaluating Paul Meyer’s Hagiographic Hypothesis. Aujourdhui, ses intérêts de recherche se portent tout particulièrement sur la confection de corpus médiévaux pour l’entrainement d’HTR (Handwritten Text Recognition). Voir son CV en ligne.