L’entropie informationnelle dans le Dictionnaire universel (1701)
Le cas des étymologies
Ioana Galleron
![]()
Ioana Galleron,
« L’entropie informationnelle dans le Dictionnaire
universel (1701) »,
dans
Robert Alessi,
Marcello Vitali-Rosati (dir.),
Les éditions critiques
numériques (édition augmentée), Les Presses de l’Université de
Montréal, Montréal, 2023, ISBN : 978-2-7606-4857-9, https://www.parcoursnumeriques-pum.ca/12-editionscritiques/chapitre8.html.
version 0, 27/03/2023
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA
4.0)
Les dictionnaires sont des textes aux caractéristiques très spécifiques. Ils semblent être une forme textuelle particulièrement adaptée aux environnements numériques car ils doivent permettre une lecture non linéaire, tabulaire, qui rende possible d’accéder directement aux contenus recherchés. Les dictionnaires demandent donc une réflexion épistémologique spécifique : ils soulèvent des questions théoriques qui leur sont propres, ils impliquent des problématiques très différentes par rapport à celles que nous avons abordées dans les chapitres précédents. Dans ce chapitre seront présentés les enjeux de numérisation et d’édition critique numérique des dictionnaires anciens. On se concentrera en particulier sur les enjeux d’encodage des étymologies qui soulèvent des problèmes intéressants, notamment relatifs au rapport entre lisibilité et fidélité à la matérialité de l’objet papier. Le contexte matériel d’émergence de l’œuvre doit être tenu en compte dans les choix techniques, dans le modèle des données et aussi dans les solutions de visualisation et d’affichage.
Parmi les fonctions les plus populaires d’Internet, la consultation
de dictionnaires en ligne occupe une place de premier rang. Qu’il
s’agisse de trouver la (ou les) définition(s) d’un mot, d’en vérifier
l’orthographe, d’en trouver la traduction dans différentes langues, il
n’y a probablement pas d’internaute qui n’y ait pas eu recours, soit
en passant par un moteur de recherche, soit en s’adressant à un
portail spécialisé, comme celui du Centre
national de ressources textuelles et lexicales en France (2021).
Plus récemment, les dictionnaires anciensIl n’existe pas de définition stricte de ce qu’est un
« dictionnaire ancien » ; il s’agit plutôt d’un corpus auquel il est
référé aussi par les syntagmes « dictionnaires d’autrefois » (par
exemple, sur le site ARTFL
qui en propose plusieurs), ou « early dictionaries » (voir le résumé
en anglais de Russon
Wooldridge et Isabelle
Leroy-Turcan (1996)). En français, ce terme
désigne les dictionnaires des XVIIe et XVIIIe
siècles, soit ceux de Nicod, Richelet, Furetière,
l’Académie, Corneille, etc.↩︎
ont connu un important gain d’intérêt, en raison de la perspective
historique qu’ils offrent sur l’évolution morpho-syntaxique et
sémantique des langues. Des travaux de coordination des campagnes de
numérisation de tels dictionnaires ont été entrepris dans le cadre
d’actions de coopération scientifique et techniqueVoir les travaux du réseau européen de lexicographie
numérique (2013).↩︎,
mais aussi dans le cadre d’associations savantesDARIAH Working group sur « Lexical
ressources », impliqué dans la construction de la norme
TEI-Lex.0 (2021), ou bien l’association
européenne de lexicographie (2016).↩︎.
À la différence des dictionnaires monolingues ou bilingues contemporains, les dictionnaires anciens posent des problèmes spécifiques, liés principalement à leur absence de standardisation. La forme moderne du dictionnaire, qui présente les informations linguistiques dans un ordre précis et utilise un jeu constant d’abréviations, ne se stabilise qu’au XIXe siècle (Corbin et Gasiglia 2014). De plus, tout au long du XVIIIe siècle, en Europe, le dictionnaire de langue est également un dictionnaire de choses (Pruvost 2006), parfois avec une forte tendance encyclopédique (Galleron et Williams, soumis). Après avoir constitué une source d’intérêt pour les lecteurs de l’époque, cette diversité d’objectifs et donc de contenus en fait des ouvrages fascinants pour les historiens des mentalités, des sciences et des langues. Mais elle confronte aussi l’éditeur scientifique en régime numérique à une série de défis particulièrement ardus. Sur la base d’un travail entrepris pour l’édition numérique du Dictionnaire universel (DU) de 1701, travail et dictionnaire qui seront plus amplement décrits dans ce qui suit, il s’agit de présenter ces différents défis, ainsi que quelques pistes pour les relever.
Ce chapitre se focalisera plus précisément sur les sections étymologiques des entrées du DU. En effet, pour agrémenter le dictionnaire (une notion et une promesse sur lesquelles je vais revenir), l’abbé Furetière propose des étymologies pour certains motsEntre 13 % et 30 % des entrées contiennent une section étymologique ; les chiffres les plus élevés s’enregistrent dans le premier volume (29 % d’étymologies pour la lettre A, 19 % pour la lettre B, etc.), mais celles-ci apparaissent tout au long du dictionnaire.↩︎, et Basnage de Beauval, son continuateur, effectue sur cet aspect aussi un travail de révision, de correction et parfois d’augmentation, comme dans le reste du dictionnaire. Or, les étymologies font intervenir des mots et des syntagmes étrangers, à partir desquels est issu le mot vedette, ou bien constituant des équivalents du mot vedette dans d’autres langues. Elles posent ainsi la question de la représentation des liens, parfois très complexes, entre étymon, mot expliqué et équivalents de ce mot dans d’autres langues.
Comme le montrent Bowers et
Romary
(2017), la
modélisation puis l’expression numérique de l’information étymologique
est un domaine dans lequel de nombreux progrès restent à faire. En
dépit de propositions séminales comme celles de Crist (2005) et Salmon-Alt
(2006), et de l’existence
d’une étiquette dédiée dans la xml
TEI
<etym>,
l’encodage de l’étymon, de ses descendants à différents stades de
l’histoire de la langue, des formes existant parallèlement dans
d’autres langues et des formes concurrentes dans une même langue donne
lieu à des pratiques peu systématiques, voire divergentesOn devrait ajouter « quand elle est tentée ». En
effet, la plupart des exemples disponibles sur le site de TEI-C,
ainsi que plus largement sur la toile, n’encodent pas du tout le
contenu de <etym>,
qui est donc présenté comme du texte simple.↩︎. Pour s’en tenir au premier terme
de cette énumération, on notera que TEI
Lex-0 : A Baseline Encoding for Lexicographic Data (2021)
recommande l’utilisation de <mentionned>,
Bowers et
Romary
(2017)
<cit type="etymon">,
et que dans BASNUM,
Projet ANR (2018) nous avons procédé, du
moins dans un premier temps, avec <foreign>
pour les cas de mots hérités (du latin et du grec) et empruntés (de
l’allemand, l’arabe, l’espagnol, l’italien, etc.) L’objectif de cette
présentation est de contribuer au progrès vers de bonnes pratiques en
la matière, en testant les propositions déjà faites et en mettant en
lumière de nouveaux aspects à l’expression numérique de laquelle il
convient de réfléchir afin de gérer le multilinguisme dans les
dictionnaires, mais aussi plus largement dans d’autres types
d’ouvrages.
Dans un premier temps, je présenterai rapidement le Dictionnaire universel, ainsi que le projet BASNUM, dédié à sa numérisation. J’évoquerai ensuite le modèle d’encodage profond proposé par Bowers et Romary (2017) et son adaptation au Basnage, en raison des spécificités des sections étymologiques des entrées de ce dictionnaire. Je finirai par une réflexion sur la visualisation des éditions critiques numériques de dictionnaires, avec une focalisation sur la question particulière de la visualisation des relations entre les langues que proposent les sections étymologiques.
Du Furetière à BASNUM
Le Dictionnaire universel est publié en 1690, de façon posthume, par Antoine Furetière (1619-1688), qui mène à son sujet une longue bataille avec l’Académie française, dont il est membre de 1662 à 1685. Sans entrer dans les détails de cette querelle, fort bien documentée ailleurs (Rey 2006; Roy-Garibal 2006), rappelons qu’à la différence de la prestigieuse institution, qui cherche à fixer « le bel usage », Furetière se propose de couvrir l’intégralité de la langue, sans distinction entre termes hauts et bas, et en donnant un maximum d’éléments des langages spécialisés. De plus, comme l’indique Pierre Bayle dans la préface qu’il écrit pour l’ouvrage, Furetière est attentif à éviter la « sécheresse » (1690) dans la présentation des mots, de leurs usages, de leurs significations ; les étymologies, ou plutôt une série d’informations historiques sur la provenance et les sens d’origine des mots, sont un des éléments grâce auxquels l’ouvrage « ne permet pas que le lecteur fasse beaucoup de chemin sans apprendre quelque chose qui en vaut la peine » (1690). Toutefois, en dépit des différences de méthode et d’esprit qu’il souligne à maintes reprises, Furetière n’a pas gain de cause en France, et se voit obligé de faire publier son dictionnaire à La Haye.
Dès la parution de l’ouvrage, et nonobstant son succès, les libraires hollandais Arnout et Reynier Leers sont conscients de ses défauts et souhaitent en publier une seconde édition. À la recommandation de Pierre Bayle, ils s’adressent à Henri Basnage de Beauval, immigré français de religion protestante, ayant fui sa Normandie natale après la révocation de l’édit de Nantes (Graveleau 2018). Après quelques essais, Basnage de Beauval accepte de s’atteler à la tâche, qui mène à la publication d’une seconde édition du Dictionnaire universel en 1701. Comme indiqué sur la page de titre, celui-ci a été « revu, corrigé et augmenté » ; prolongeant l’intention encyclopédique de Furetière, Basnage augmente le texte de plus d’un tiers, à la fois par l’introduction de nouvelles entrées, par l’ajout de sens, par la réécriture complète de certaines définitions et, surtout, par des exemples tirés de différents auteurs ou créés ad hoc. Le traitement des étymologies ne fait pas exception à cette règle, même si ce n’est pas le domaine de prédilection de Basnage (plus intéressé par la terminologie). Les étymologies qu’il conserve de l’édition Furetière constituent souvent le point à partir duquel il « relance » l’entrée. On voit, par exemple, l’ajoute de l’entrée liée « Faire le fanal » après celle de « Fanal », ou encore celui d’un second sens dans l’entrée du substantif « Fange ».
Dans le cadre du projet ANR BASNUM, l’édition de 1701 du Dictionnaire universel – désignée parfois, dans ce qui suit, comme « le Basnage » – est numérisée et étudiée. L’acquisition du texte a été effectuée grâce à l’entraînement d’un modèle de reconnaissance optique des caractères sous Transkribus (ReadCoop 2021). Dans un second temps, les principales structures du dictionnaire (mot vedette, informations grammaticales, sens et définitions, étymologies, entrées liées et renvois) ont été identifiées grâce à l’entraînement d’une série de modèles avec GROBID-Dictionaries (Khemakhem et al. 2017). Les fichiers xml TEI obtenus ont fait, dans un troisième temps, l’objet d’une série de transformations XSLT, afin d’améliorer leur encodage, et ont été nettoyés et corrigés manuellement. Les résultats de l’océrisation comme de l’annotation structurelle non corrigée sont d’ores et déjà disponibles à la communauté (2021).
Je m’appuierai dans ce qui suit principalement sur le fichier xml TEI de la lettre F, qui présente l’avantage d’être à la fois relativement court (1174 entrées) et significatif de la pratique « moyenne » du DU en matière d’étymologies (194 entrées présentent une section étymologique, soit 16,5%). À l’échelle du dictionnaire, toutes les étymologies ont été identifiées, mais la plupart n’ont pas subi un encodage en profondeur, ou bien ont fait l’objet d’un encodage partiel – pour l’identification des langues sources des étymons, par exemple. Les expérimentations les plus poussées, qui sont présentées dans ce qui suit, ont été menées sur cette lettre F.
Encoder les étymologies
Les étymologies proposées par le Basnage sont à la fois bien plus simples que ce que l’on peut trouver dans un dictionnaire moderne, et très compliquées à prendre en charge en raison de leur irrégularité, comme de la multitude d’informations qu’elles offrent. Ainsi, Furetière et Basnage ne s’attardent pas sur la description des mécanismes par lesquels un mot issu du latin ou d’une autre langue est devenu un mot français, préférant accumuler d’autres types d’informations. On le voit dans l’exemple suivant, où l’évolution phonétique, graphique et sémantique depuis « fabrica » et jusqu’à « fabrique » ne fait pas l’objet de la présentationOn peut imaginer que, dans ce cas, Furetière et Basnage ont considéré transparent le passage de l’étymon au mot français, mais il existe des étymologies plus surprenantes, impliquant des processus phonétiques et sémantiques complexes, qu’ils ne détaillent pas non plus, laissant potentiellement le lecteur dans une certaine perplexité. Voir en ce sens les étymologies pour « Forvetu », « Fou », « Fouiller », etc.↩︎, mais où l’on trouve en revanche une note sur l’usage français, puis un rappel historique :
FABRIQUE. s. f. […] Ce mot vient du latin fabrica, qui proprement signifie forge : et de là vient sans doute que le mot de fabrique se prend quelquefois pour le lieu où l’on fabrique la monnaie. Les Anciens érigeaient des autels au milieu des fabriques de la monnaieToutes les citations du Basnage (1701) proviennent du second tome. La page n’est pas indiquée, car le dictionnaire n’est pas paginé. L’orthographe a été modernisée tacitement.↩︎.
De plus, le dictionnaire ne fait pas vraiment de distinction
conceptuelle entre mots hérités, mots empruntés et mots issus d’autres
mécanismes (composition, grammaticalisation, métaphorisation, entre
autres), même si l’on y trouve des exemples illustrant chacun de ces
cas. Pour s’en tenir aux deux premiers types, qui touchent directement
à la question de la gestion du multilinguisme, il est significatif que
nos lexicographes utilisent dans un cas comme dans l’autre la formule
neutre « ce mot vient deOn trouve également « prend son origine dans », « est
dérivé du », « X dérive ce mot dev », et d’autres menues variations
sur ces formules introductrices. « Ce mot vient » est tellement usuel,
qu’on le trouve également pour introduire un nom propre à partir
duquel un nom commun est formé par antonomase, procédé bien
particulier pour lequel on aurait attendu un autre traitement :
« Fierabras. […] Ce mot vient de Guillaume Fierabrach, c’est-à-dire,
bras de fer, qui était frère de Robert Guiscard qui conquit la Sicile,
et était un fort vaillant homme. »↩︎ », sans chercher à
indiquer autrement que par la mention de la langue les cas où il
s’agit d’un héritage (« ce mot vient du latin ») de ceux des mots
entrés ultérieurement dans la langue, à partir d’autres sources et
traditionsLa perspective adoptée actuellement dans le cadre du
projet BASNUM étant plutôt « éditoriale » que « lexicale » (voir en ce
sens le chapitre « Dictionaries »
des Guidelines, TEI-C), la distinction entre les deux
mécanismes n’est pas faite au moyen d’un @type placé sur l’étymon, mais il n’est pas
impossible d’y procéder ultérieurement, peut-être dans le cadre d’une
campagne de crowd-sourcing.↩︎ :
FUMIER. s. m. […] Ce mot vient du latin fimus ou fimetum.
FRASQUE. s. f. […] Ménage tient que ce mot vient du frasca italien, qui signifie une branche, et figurément une bagatelle ou embarras.
On n’a pas besoin, dans ce cas, d’annoter les différents états du
mot, avec les changements phonétiques et morphosyntaxiques subis à
travers le temps, auxquels Bowers et
Romary
(2017)
consacrent une bonne partie de leurs réflexions. Pour autant,
l’encodage des étymologies ne se simplifie pas. En effet, l’exemple
suivant, réalisé selon les recommandations de l’article cité, présente
plusieurs erreurs de structure par rapport aux recommandations de la
TEI,
ni <oRef>, ni
<gloss> ne
pouvant être directement les enfants de <cit>
selon ces dernières :
<etym>
<lbl>Ce mot vient apparemment à</lbl>
<cit type="etymon">
<oRef xml:lang="la">frugibus</oRef><pc>,</pc>
<gloss>qui sont la plus simple, la plus saine & la plus
ancienne nourriture de l'homme<pc>.</pc></gloss>
</cit>
</etym>Le problème est relativement facile à contourner, soit en
introduisant un <quote>
qui enveloppe tous les contenus de <cit>,
soit en adaptant le schéma par rapport auquel se fait la validation.
Néanmoins, les deux solutions ont leurs propres inconvénients. En ce
qui concerne la seconde, elle pose le problème de l’interopérabilité,
à moins que l’on ne se dirige vers une modification des
Guidelines, suggérée par les deux auteurs. Quant à la
première, si elle règle le problème de <oRef> qui
peut être un enfant de <quote>,
elle demande soit de transformer la glose en une deuxième citationCette solution semble préférée par Bowers et
Romary
(2017). Il
n’existe pas d’exemple parfaitement comparable à celui donné ici, mais
c’est ce que l’on peut déduire du traitement qu’ils proposent pour
« ntuchi » (rein, en langue Mixtepec-Mixtec), « kiti »
(« animal/cheval » dans la même langue), ou « besides » (en
anglais).↩︎, soit de la « sortir » de
l’élément <cit>, ce
qui fonctionne parfaitement dans ce cas simple, mais qui pose d’autres
problèmes lorsqu’on a des étymons concurrents ou « en cascadeJe désigne par le premier terme le cas où le DU propose
plusieurs étymons possibles pour un même mot vedette, respectivement
le cas où l’étymon d’un étymon est donné : « Ce mot vient de
flasco, qui a été formé de l’allemand flasch, qui
signifie bouteille de vin. »↩︎ », dont certains sont glosés et
d’autres non : l’absence d’un élément enveloppant, qui manifeste le
lien entre la forme et son équivalent dans une autre langue, est un
vrai problème dans cette situation, fort fréquente dans le DU.
Une alternative à ces différentes solutions, et qui aurait
l’avantage de simplifier l’encodage, est de renoncer à <cit>, et
de s’en tenir à un simple <oRef> ;
cet élément accepte l’attribut @type, qui
peut dès lors porter la valeur « etymon », dont l’utilisation
constitue un des apports les plus précieux de l’encodage proposé par
Bowers et
Romary. De
plus, rien n’empêche de placer directement sur <oRef> les
autres attributs dont les deux auteurs recommandent l’utilisation
(@xml:lang, @xml:id, @next et @prev). Je propose d’y ajouter @corresp (pour indiquer le mot auquel l’étymon se
réfère, et qui n’est pas toujours le mot vedette, dans un dictionnaire
ancien), et @target, si l’objectif est de
lier l’étymon à sa définition dans une autre ressource lexicographique
numérique (désignée ici par #frugal_ext).
L’encodage devient ainsi :
<etym>
<lbl>Ce mot vient apparemment à</lbl>
<oRef type="etymon" xml:lang="la" corresp="#frugal"
target="#frugal_ext">frugibus</oRef><pc>,</pc>
<gloss>qui sont la plus simple, la plus saine et la plus ancienne
nourriture de l'homme<pc>.</pc></gloss>
</etym>Les étymologies « en cascade », ou le besoin d’ajouter des dates à
partir desquelles et jusqu’auxquelles certaines formes ont été
utilisées, peuvent être réglées dans ce cas par l’utilisation de
plusieurs <etym>
imbriquées, comme dans l’exemple suivant :
<etym>
<lbl>Ce mot vient du</lbl>
<lang>latin</lang>
<oRef type="etymon" xml:lang="la" xml:id="folium"
corresp="#feuille">folium</oRef><pc>,</pc>
<etym>
<lbl>du</lbl>
<lang>grec</lang>
<oRef type="etymon" xml:lang="gr"
corresp="#folium">phyllon</oRef><pc>.</pc>
</etym> [...]
</etym>On peut noter ici l’utilisation de l’attribut @corresp, déjà employé plus haut pour « Frugal »,
et qui permet d’indiquer que « phyllon » est l’étymon de « folium »,
et non pas du mot-vedette « Feuille ». Cet usage de @corresp, différent de la pratique recommandée par
Bowers et
Romary,
permet, en outre, de régler le cas des étymologies groupées, où le
même étymon renvoie à plusieurs vedettes, que Furetière
et Basnage
pratiquent soit pour économiser de l’espace et de l’énergie, soit,
plus probablement, parce qu’ils ne savent pas démêler quel mot d’une
famille est issu le premier de l’étymon latin, et comment celle-ci
s’est complétée à travers le temps :
<etym>
<lbl>Ces mots viennent du</lbl>
<lang>latin</lang>
<oRef type="etymon" xml:id="la" corresp="#fretille #fretillement
#fretiller">fritillus</oRef><pc>,</pc>
<gloss>qui signifie, un cornet qui sert à remuer et à jeter les
dés</gloss><pc>.</pc>
</etym>Outre les étymologies imbriquées, le DU présente de nombreux cas de concaténation, là où Furetière ou Basnage se plaisent à citer des opinions divergentes en la matière, sans trancher. On peut donc trouver la situation suivante :
<etym>
<etym n="1">
<ref>Menage</ref>
<lbl>derive ce mot de</lbl>
<oRef type="etymon" xml:id="felonia"
corresp="#felonnie">felonia</oRef><pc>,</pc>
<lbl>qui vient de</lbl>
<oRef type="lemma" xml:id="felo" corresp="#felonia">felo</oRef> ou
<oRef type="variant" xml:id="fello"
corresp="#felonia">fello</oRef><pc>,</pc>
<note>ou qui se trouve dans <bibl>les Capitulaires de Charles le
Chauve</bibl></note><pc>;</pc>
<lbl>et croit qu'il a été fait de</lbl>
<oRef type="etymon" corresp="#felonia">feelen</oRef>
<lang>allemand</lang><pc>,</pc>
<gloss>qui signifie, faillir</gloss><pc>.</pc>
</etym>
<etym n="2">
<ref>Quelques-uns</ref>
<lbl>le dérivent du</lbl>
<lang>latin</lang>
<oRef type="etymon" corresp="#felonnie">vilania</oRef><pc>.</pc>
</etym>
</etym>Dans un tel cas, on peut a minima numéroter les
étymologies, comme cela a été fait dans l’exemple donné, mais il
serait également utile de pouvoir indiquer qu’on a affaire à des
propositions concurrentes, et non pas consensuelles, comme dans le cas
des étymologies simples ou « en cascade ». L’élaboration d’une
typologie des étymologies (primaires ou secondaires, uniques ou
variantes) serait intéressante dans cette perspective. Il convient
tout de même de veiller à ne pas subvertir la possibilité de désigner
le mode d’enrichissement lexicographique (par héritage, emprunt,
composition, etc.), en distinguant l’attribut dédié à exprimer ce
dernier (@type, dans Bowers et
Romary
(2017)) de
celui destiné à l’analyse des différentes constellations étymologiques
(peut-être @subtype, ou @ana).
Un cas non discuté dans la proposition d’encodage profond des étymologies est celui des sections où Furetière ou Basnage se contentent de donner l’équivalent latin d’un mot français, sans indiquer qu’il s’agit d’un étymon, ou sans que le mot en soit réellement un, et parfois en concurrence avec une section étymologique. Dans les cas simples, comme « en latin ferula », que l’on trouve sous l’entrée « Férule », il est facile de considérer qu’on a affaire à une étymologie simplifiée, et traiter la proposition en conséquence. Mais « curruca » n’a rien à voir, étymologiquement parlant, avec « Fauvette ». Suivant les Guidelines, ce type de phrase est à traiter comme un équivalent de traduction (translation equivalent), mais ce mode de traitement s’avère rapidement inapproprié dans de nombreux cas, où le dictionnaire accumule les informations encyclopédiques :
FAUVETTE. s. f. […] Il y a des faucons riviéreux, d’autres champêtres, propres à voler sur les rivières, ou les campagnes : en latin, falco, triorches, buteo, et en général, accipiter, qui est le nom de la meilleure espèce, qui a donné le nom aux autres.
Jean de Janua dit que ce nom vient de ce qu’il a les ongles recourbés qui ressemblent à une faux sylvestre. Giraldus le dérive à falcando, parce qu’il vole en tournant comme une faux. Frideric Lempereur a bien écrit des faucons en son Art de la Chasse. Albert le Grand, Jacques Auguste de Thou dans sa Fauconnerie, etc.
La stratégie d’encodage passe ici par l’introduction d’une section étymologique, suivie d’une série d’entrées liées :
<etym>
<lbl>en latin</lbl>
<oRef type="etymon" corresp="#faucon">falco</oRef></etym>,
<xr type="hyponym">triorches</xr>,
<xr type="hyponym">buteo</xr>,
<lbl>et en général</lbl>
<xr type="hyponym">
<oRef>accipiter</oRef>,
<gloss>qui est le nom de la meilleure espèce, qui a donné le nom
aux autres.</gloss>
</xr>
<etym>
<ref>Jean de Janua</ref> etc.Conforme aux recommandations de TEI-Lex.0, cette façon
de faire reste cependant discutable, dans la mesure où elle constitue
une interprétation lexicographique plutôt qu’éditoriale du texte. On
peut ainsi se demander s’il n’aurait été préférable de traiter
l’ensemble de la phrase comme une note de Furetière
– car la paternité sur cette partie de l’entrée lui revient
entièrement – livrant ici des connaissances encyclopédiques sur la
fauconnerie, plutôt que des informations linguistiques. En restant
d’ailleurs dans la perspective lexicographique, on peut se demander si
la distinction entre « falco », traité comme un étymon, et
« triorches », « buteo », « accipiter » est juste, ou bien s’il ne
faudrait pas annoter le premier comme <xr>
également, dans la mesure où il renvoie, comme les autres termes, à
une présentation de ce type d’oiseau dans un autre ouvrage, plutôt
qu’il n’introduit un ancêtre du mot français « faucon ».
Des problèmes épineux sont également posés par les sections étymologiques dans lesquelles Furetière et Basnage donnent d’autres mots issus du même étymon, dans d’autres langues. La fortune de « fabula » est ainsi présentée non seulement en français, mais aussi en italien et en espagnol :
Ce mot vient du latin fabula, où il signifie aussi, entretien, comme on voit dans ce proverbe, Lupus in fabula, qui répond au nôtre, Qui parle du loup en voit la queue, d’où on a fait confabulari, confabulation, et les Italiens, favella, pour dire, parole. Les Espagnols disent, Morir sin fabla, ou fabuls ; pour dire, mourir intestat.
L’encodage de l’ensemble peut être fait avec le jeu d’étiquettes
mentionné plus haut, et grâce à une stratégie d’imbrication de
sections étymologiques, ainsi qu’à l’utilisation de @corresp :
<etym type="inheritage">
<lbl>Ce mot vient du</lbl>
<lang>latin</lang>
<oRef type="etymon" xml:id="fabula" xml:lang="la" corresp="#fable
#confabulari #favella">fabula</oRef><pc>,</pc>
<lbl>où il signifie aussi,</lbl>
<gloss target="#fabula">entretien</gloss><pc>,</pc>
<note type="example">comme on voit dans ce proverbe, <foreign
xml:id="proverb1" xml:lang="la">Lupus in fabula</foreign>, qui
répond au nôtre, <cit type="translation" xml:lang="fr"
corresp="#proverb1"><quote>Qui parle du loup en voit la
queue</quote></cit>,</note>
<etym type="derivation">d'où on a fait <oRef type="etymon"
xml:id="confabulari" xml:lang="la"
corresp="#confabulation">confabulari</oRef> et <oRef
xml:id="confabulation"
xml:lang="fr">confabulation</oRef></etym><pc>,</pc>
<etym type="inheritage"> et les Italiens <lang xml:lang="it"/>
<foreign xml:id="favella" xml:lang="it">favella</foreign>, pour
dire, <gloss target="#favella">parole</gloss></etym>.
<note>Les Espagnols <lang xml:lang="es"/> disent, <foreign
xml:id="idiom1" xml:lang="es">Morir sin fabla</foreign> ou
<foreign xml:id="idiom2">fabuls</foreign> ; pour dire, <cit
type="translation" corresp="#idiom1 #idiom2"><quote>Mourir
intestat</quote></cit><pc>.</pc></note>
</etym>On voit toutefois ici les limites d’un encodage étymologique qui
lie uniquement l’étymon à son dérivé, mais pas réciproquement (ex.
« confabulation »), ainsi que, plus généralement, les problèmes posés
par le besoin de relier d’autres segments (proverbes, idiomatismes),
dont le DU fournit
des équivalents de traduction. De même, l’utilisation par Furetière
et Basnage
de « Italiens » et « Espagnols » comme des équivalents de « en
italien », « en espagnol » crée une disparité de traitement, qui n’est
compensée que de façon assez insatisfaisante par l’insertion d’un
élément <lang>
vide. Enfin, la note finale suscite à son tour des interrogations,
dans la mesure où l’on peut y voir une sorte de section étymologique
qui ne donne pas le dérivé « fabla » en tant que tel, mais dans le
cadre d’un exemple, peut-être pour varier les formules au nom de la
belle expression. Au total, on peut se demander dans quelle mesure cet
encodage rend justice à la circulation du sens dans cette section, à
la complexité des liens sémantiques donnés à apercevoir par nos
lexicographes dont la figure suivante donne la représentation
schématique.
Figure 8.a – Schématisation de l’étymologie de « Fabula » dans le Dictionnaire universel, 1701
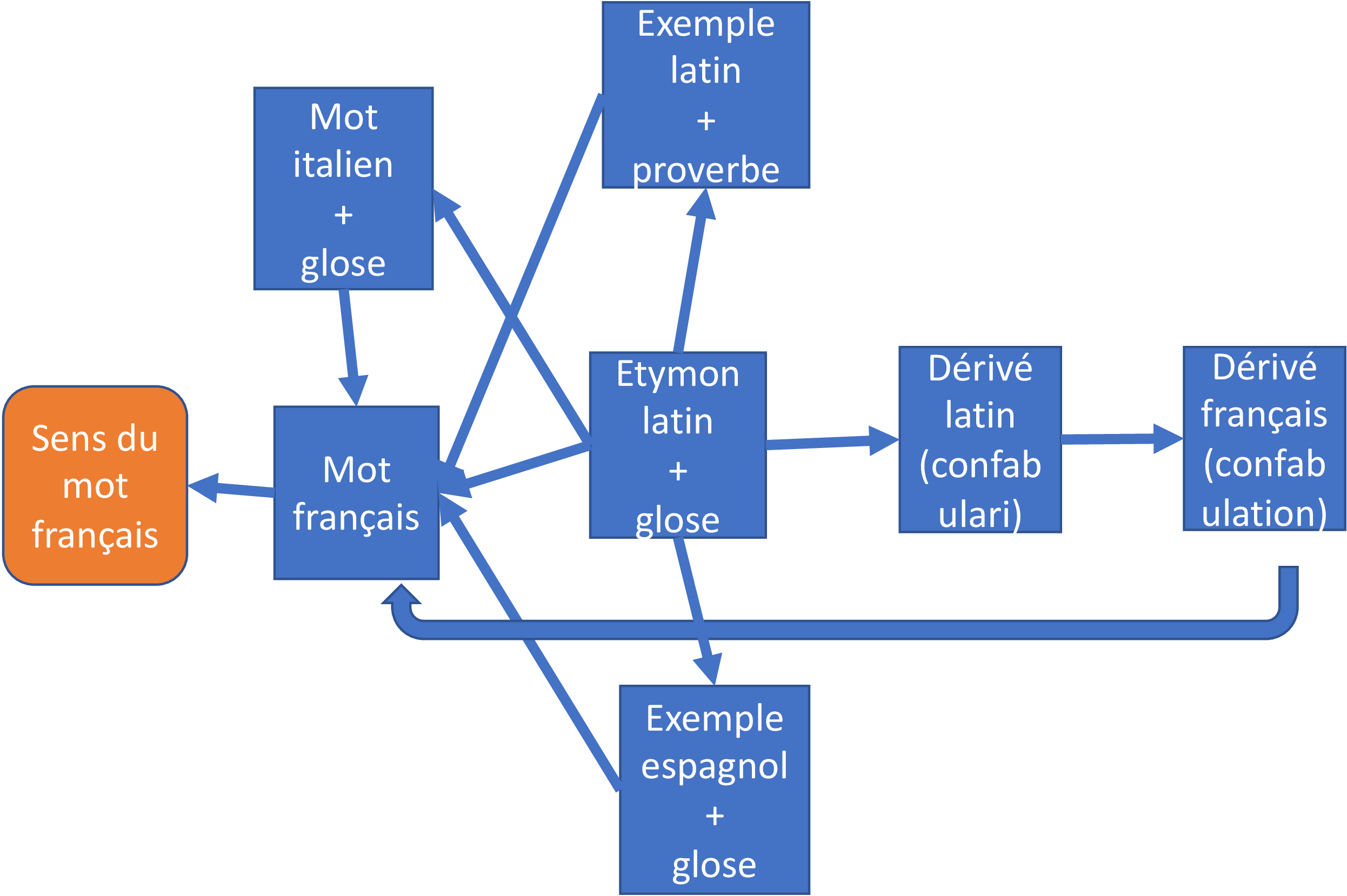
Proposé par auteur le 2023-03-27
Un dernier problème posé par le multilinguisme du dictionnaire est la gestion de la référence aux différentes langues. Pour bon nombre d’entre elles (latin, allemand, italien, espagnol, etc.) des abréviations consensuelles existent au niveau international. Cependant, comme le remarquent Bowers et Romary (2017), les normes internationales (2021) sont encore incomplètes en la matière. À ceci s’ajoute le fait que Furetière et Basnage utilisent des dénominations obsolètes ou incertaines, comme « bas breton », « basse latinité », « saxon », « grec barbare », pour lesquels il serait difficile de suggérer l’ajout de codes, car on ne sait pas exactement à quel état de la langue les deux auteurs font référence en les utilisant. Même en visant l’alignement avec les vocabulaires contrôlés existants sur le Web, l’encodage du DU implique donc une part nécessaire de non-conformité et de personnalisation.
Visualiser le multilinguisme du Dictionnaire universel
Tout comme il n’existe pas de bonnes pratiques stabilisées pour encoder les étymologies, un consensus ne semble pas non plus s’être dégagé jusqu’à présent quant à ce que l’on doit attendre de la vitrine web d’un dictionnaire numérique. Une analyse des possibilités d’interrogation et de navigation offertes par quatre sites dédiés à des ressources de la même période, ou d’une période proche de celle de la publication du DU (Johnson’s Dictionary Online (2021) ; ENCCRE - Édition Numérique Collaborative et CRitique de l’Encyclopédie (2021) ; (Turcan 2021)), montre que l’accent tombe différemment sur les quatre dimensions du texte patrimonial, à savoir ses métadonnées, sa structure interne, les liens entre ses différentes parties et les liens vers des sources externes. Si l’on peut, partout, rechercher un mot, soit en tant que vedette, soit dans le corps du dictionnaire, et si l’on obtient habituellement aussi bien l’entrée que l’entrée en contexte, en fonction des sites on aura ou non accès au document xml, on disposera de paratextes plus ou moins fournis, on identifiera plus ou moins facilement l’organisation des entrées et on bénéficiera de façon variable de liens cliquables vers les sources, l’intertexte, les concepts liés ou les notices encyclopédiques au sujet des différents auteurs cités.
L’objet de cette section n’est toutefois pas de s’engager dans une réflexion globale sur la façon de satisfaire ces différentes attentes, mais plutôt de s’interroger sur la façon dont l’utilisateur d’un site peut être averti quant à la multitude d’informations existantes dans l’édition numérique d’un dictionnaire, sans l’accabler sous un trop grand nombre de pointeurs, qui nuirait à la lisibilité du texte. L’accès au fichier xml garantit la visibilité de l’encodage effectué, mais peu nombreux sont les lectorats qui se dirigent d’emblée vers cette ressource. La solution la plus courante est de prévoir une description de l’encodage, et un ou plusieurs formulaires de recherche couvrant l’ensemble des balises utilisées. Toutefois, compte tenu de la multitude de ces dernières, les croisements possibles sont potentiellement très complexes ; ceci reviendrait, d’une certaine manière, à réinventer à travers une interface html des outils comme eXist ou BaseX, qui permettent d’extraire de l’information au moyen de XQueries, via des interfaces graphiques. Un choix possible est de signaler au lecteur l’existence d’un découpage plus fin des informations encodées, afin de le diriger, d’une part, vers la description de l’annotation effectuée, et d’autre part vers le fichier xml contenant cette annotation, qu’il pourra par conséquent télécharger et parser avec ses propres moyens.
En s’inspirant du système GROBID, qui applique des
modèles en cascade au texte afin d’en extraire les structures, on peut
imaginer une consultation progressive du dictionnaire, qui va de plus
en plus en profondeur pour observer les relations entre les différents
composants. Ainsi, lors de la première requête (recherche d’un
mot-vedette), plutôt que de donner uniquement le texte, un jeu
d’arrière-plans de couleur peut déjà signifier l’existence d’une série
de blocs contenant des annotations supplémentaires. Dans l’exemple
suivant, outre l’utilisation des italiques pour la reprise du mot
vedette, qui est habituelle en lexicographie, et les hyperliens vers
des références externes, signifiés par le lettrage bleu souligné, le
texte surligné en jaune indique la définition, en parme les différents
exemples, et en vert la section étymologique :
FAUTEUIL. : s. m. Chaise à bras avec un dossier. Un meuble de chambre doit consister en fauteuils, chaises et sièges pliants. On présente le fauteuil aux personnes de qualité comme le siège le plus honorable. Plusieurs femmes se sont querellées pour le rang, pour le fauteuil. Cet incivil s’établit par tout familièrement dans un fauteuil, et ne l’abandonne jamais à personne. La Br. On disait autrefois, faudesteuil et faudestuef, d’où par contraction on a fait fauteuil. Ce mot vient de faldistorium, qui est une chaise épiscopale, ou de l’officier célébrant, posée à côté de l’autel. Il est dérivé de l’allemand fald, qui signifie clos, enceinte, et tout lieu fermé, à cause que les chaires des évêques étaient fermées de balustres. Ménage après Spelmannus. Du Cange le dérive de l’allemand faldan, qui signifiait un siège pliant; que Covarruvias dérive de l’espagnol falda, qui signifie une robe de femme ayant plusieurs plis. Dans la basse latinité on l’appelait faudestola.
On trouve ici surlignée en jaune la définition à proprement parler, suivie d’une section d’exemples et citations en rose. La couleur bleue signifie qu’un lien hypertexte est ajouté. La partie surlignée en vert correspond à l’étymologie. En cliquant sur la dernière partie, l’utilisateur accède à une vue plus fine de sa structure interne :
|On disait autrefois, faudesteuil et faudestuef, d’où par contraction on a fait fauteuil. ∥Ce mot vient de faldistorium, qui est une chaise épiscopale, ou d’officier célébrant, posée à côté de l’autel. Il est dérivé de l’allemand fald, qui signifie clos, enceinte, et tout lieu fermé, à cause que les chaires des évêques étaient fermées de balustres. Ménage après Spelmannus. ∥ Du Cange le dérive de l’allemand faldan, qui signifie siège pliant ; que Covarruvias dérive de l’espagnol falda, qui signifie une robe de femme ayant plusieurs plis. ∥ Dans la basse latinité on l’appelait faudestola.|
Les formes intermédiaires du mot sont ici indiquées en jaune, et les étymons en gras. Les langues sont saisies en rose. Les barres verticales servent à indiquer les différentes parties de l’étymologie ; on a ici trois dérivés intermédiaires, non datés ou vaguement datés, et donnés dans le désordre, puisque « faudesteuil » d’« autrefois », probablement l’ancien français, vient avant la forme de la « basse latinité », ainsi que deux étymologies concurrentes, celle de Ménage d’après Spelmannus et celle de Du Cange et Covarruvias. Bon nombre d’informations restent cependant non matérialisées, comme les gloses, les relations entre ces différentes parties ou les dérivés issus de chaque étymon. Se pose aussi la question de la représentation à adopter pour le cas où un étymon est lui-même le dérivé d’un autre, comme on l’a vu plus haut pour « folium ». Le juste équilibre entre matérialisation typographique du multilinguisme et la lisibilité du passage reste encore à trouver.
Conclusions
Les étymologies dans les dictionnaires, plus anciens ou plus modernes, restent un des objets les plus fascinants d’étude, car elles concentrent sur un très bref espace des discours très divers et des mots issus de plusieurs langues. Même si les informations fournies sont parfois fausses, mal comprises ou incomplètes, on a là autant de relais de transmission d’un passé que l’on ne cesse de réévaluer, de redécouvrir et de comprendre.
En même temps, la gestion des étymologies est un des problèmes les plus complexes, et peut-être les plus spécifiques, des opportunités et des défis de l’édition numérique. Si les dictionnaires papier ont travaillé à la standardisation des informations, l’éditeur numérique s’interroge sur des questions supplémentaires de représentation de l’organisation interne et des liens entre les étymologies dans le cadre d’un même ouvrage, ou entre des ouvrages différents. À la lecture linéaire, il ajoute ainsi non seulement une facilité d’accès sans précédent, mais aussi une possibilité de lecture tabulaire, croisée, et affinée.
Toutefois, trouver la bonne façon d’implémenter ces modes de lecture supplémentaire demande de poursuivre les tests sur une grande variété d’exemples afin d’identifier les limites des propositions déjà faites et de les améliorer. C’est donc se placer dans un temps nécessairement long, souvent peu compatible avec la rapidité exigée par les financeurs dans la production des résultats de la recherche. Aucun encodage “en masse” n’est toutefois envisageable avant de s’être mis d’accord sur de bonnes pratiques, en absence desquelles aucune automatisation du processus n’est d’ailleurs possible.
Références
Accéder à cette bibliographie sur Zotero
Ioana Galleron
Ioana Galleron est professeur de littérature française et humanités numériques à l’université de Sorbonne-Nouvelle. Elle travaille plus particulièrement sur des textes du XVIIe et XVIIIe siècle français, qu’elle explore avec des outils traditionnels (dans une perspective de « close reading ») et avec des outils des humanités numériques (encodage, annotation et « distant reading »). Elle est l’auteur de plusieurs éditions électroniques, livrées ou en cours de réalisation : théâtre de la première moitié du XVIIIe siècle, Dictionnaire universel d’Antoine Furetière, revu, augmenté et corrigé par Basnage de Beauval, e. a. Elle a coordonné le numéro spécial de la Revue d’histoire du théâtre consacré à la thématique « Théâtre et humanités numériques », et a publié chez OUSE en 2017 un volume sur La Comédie de mœurs sous l’Ancien régime : poétique et histoire.